경희대학교 김정욱 교수님의 컴퓨터 구조 수업을 기반으로 정리한 글입니다.
Explanation of 32 Registers
32 Registers
- $zero: contains 0 value
- $a0 ~ $a3: function argument, 함수를 호출할 때 전달하는 인자
- $v0, $v1: return values, 최종 결과값을 전달할 때 사용
- $t0 ~ $t9: temporary register (do not have to preserve), 덮어쓰기 가능 (메모리에 저장 X)
- $s0 ~ $s7: saved registers (preserve), 덮어쓰기 불가능 (메모리에 저장)
- $gp: global pointer (to access static data ex) constant value)
- $sp: stack pointer (current point in stack), array(stack)을 가리키는, 즉 주소값을 담고 있는 pointer
- $fp: frame pointer (points the first item on the stack), array의 첫 번째 주소값이 담
- $ra: stores the address of the previous function, return address, callee가 callee로 돌아갈 때 사용
※ $k0(26), $k1(27): Reserved for OS kernel
a register를 이용해 caller에서 callee로 인자를 전달하면,
그 후에 return 값이 있는 경우에는 v register와 ra register는 함께 움직인다고 보면 된다. (v - return value, ra- return address)
물론, return 값이 없는 경우에는 ra register만 움직인다.

▶ Register number, Preserved on call
a 레지스터가 4개, 즉 argument를 4개밖에 못 받는데,
만약 10개를 받아야 하면 어떻게 해야 할까?
처음 4개의 데이터를 a 레지스터에 로드, ($a0 ~ $a3 사용)
나머지 6개의 데이터는 레지스터에 모두 담을 수 없으므로 메모리에 저장한다.
이때, 메모리에 데이터를 저장하기 위해서 t register 혹은 s register에 임시로 값을 저장한다.
이렇게 4개의 데이터를 먼저 처리한 후, 메모리에 저장해둔 나머지 데이터 중,
다음 4개의 데이터를 다시 a 레지스터에 로드하고, 동일한 방식으로 처리한다.
Supporting Procedures in Computer Hardware
Procedure (=Function)

▶ caller: 호출하는 함수 (함수를 호출 하는 주체) / callee: 호출 당하는 함수 (함수를 호출 당하는 객체)
※ caller/callee는 두 함수 간의 상대적 관계를 나타내는 것으로, 어떤 함수에겐 callee인 함수가 또 다른 어떤 함수에겐 caller일 수 있다.
Callee procedure를 수행할 때, register에 저장된 값이 사라질 수 있다.
때문에, Callee procedure를 마치고 다시 Caller procedure로 돌아올 때,
기존 Caller procedure에서 다시 활용하게 될 수 있는 변수 값을 memory에 미리 저장해야 한다
이때, 보존되어야 하는 값이기에 s register를 사용해 주어야 한다.
ex) 위 그림 속 code에서 x, y

▶ register -> Memory
레지스터 값이 바뀌면 안 될 때 해결 방법
- 1번째: 값을 저장한 해당 레지스터를 그 이후에 사용 X
- 2번째: 메모리에 저장
register 개수가 적기에 2번째 방법이 더 현명하다.
예를 들어, $s0 ~ $s7의 saved register는 총 8개 밖에 없는데, 이 값을 보존하려면,
callee가 x, y 값이 담긴 $s0와 $s1을 사용하지 못하게 해야 한다. (비효율적임)
때문에, x와 y 값들은 메모리에 임시로 저장하여 saved register를 자유롭게 해야 한다.
※ s register가 아닌 t register를 사용하면 저장하지 않아도 되는 변수로 인식되어, 결과적으로 덮어 씌워져 값 보존되지 않는다.
메모리에 어떤 식으로 저장해야 할까?

▶ Stack Architecture
- 1. Save the contents of $s1 and $s0 of Caller procedure to the memory stack (now $s1, $s0 are free!) using push -> Register $sp stores address of the memory that contains the contents of register $s0
- 2. Process Callee procedure (function)
- 3. Return to the original Caller procedure
- 4. Restore using pop in the memory stack
※ High address, Low address는 메모리 입장에서 말하는 것이다. 즉, 실제 메모리는 위에서 아래로 쌓는 구조이다. 때문에 $s1의 값이 $s0의 값보다 먼저 담긴 것이다.
Dividing 18 of the registers ($t0 ~ $t9, $s0 ~ $s7) into two groups
- $t0 ~ $t9: temporary registers are not preserved by the callee on a procedure call
- $s0 ~ $s7: saved registers that must be preserved on a procedure call (callee 진입 전, 메모리에 저장)
Stack
stack은 점차적으로 쌓아 내리는 것으로, 메모리의 입장에선 stack에 엄청나게 많은 값이 담긴다.
이러한 stack은 가장 늦게 들어온 데이터가 가장 먼저 나가는 a last-in-first-out 후입선출 방식이다. (LIFO)
이때, $sp 즉 stack pointer register는 현재 stack(메모리)에서 가리키고 있는 위치를 가리키는 포인터로,
지금 쌓은 위치는 여기로, 먼저 빼야 하는 거는 여기다, 즉 가장 낮은 지점을 표시한다.
즉, $sp는 the most recently allocated address in the stack, 가장 최근에 저장된 데이터의 주소값이 담긴 포인터이다.
register - stack 이동 관련 용어
- push: Placing data onto the stack, 값 넣는 것
- pop: removing data from the stack, 값 꺼내는 것
위에서 x, y는 잃어버리면 안 되는 값으로, 저장해야 한다고 했는데, (Suppose x: $s0, y:$s1)
이렇게 2개 저장해야 하니 stack pointer를 두 칸 내려야 한다. (32비트 - 4 바이트씩 2개)
이 과정은 caller에서 callee로 넘어가기 직전에,
x랑 y는 사라지면 안 되니 메모리에 저장하는 과정이다. (그후, callee 수행)
callee가 다 끝나면 caller로 다시 돌아가야 하는데,
즉 메모리에 저장된 값을 원래 $s0과 $s1 register에 매핑하며 아무일도 없었던 것처럼 돌아와야 한다.
이렇게 callee로 돌아갈 때엔, 밑에 x 부분은 $s0 registe에, 위에 y 부분은 $s1 register에 할당한다.
그 후 stack pointer를 다시 올려 복구하면,
이전 stack pointer와 일치하여 아무일도 없던 것처럼 된다.
총 정리하면,
caller를 실행할 때 caller에서 아무 일도 없었던 것처럼 처리를 해야 되니까,
x와 y의 값들을 이제 메모리에다가 저장을 하고, 이제 callee가 끝나면 다시 caller로 진입하기 직전에,
$s0과 $s1의 값을 다시 꺼내서 register에 할당을 시켜놓고 caller로 다시 돌아오는 과정이다.
※ $sp를 저장할 만큼 내리기 -> 값 저장 -> 값 꺼내기 -> $sp를 다시 꺼낸 만큼 올리기
MIPS code
addi $sp, $sp, -8 # 스택 포인터를 8만큼 내려서 x와 y를 저장할 공간 확보▶ stack 공간 확보
이때, 2개를 할당하는데 8만큼 내리는 이유는, byte addressing으로 2개 × 4 (byte addressing)이기 때문이다.
이렇게 stack pointer를 내린 후, 거기에 x, y 집어넣고 callee 를 수행하는 것이다. (sw: store word)
그 후 다시 caller로 가기 전, x, y를 $s0, $s1 레지스터에 값을 넣고, (lw: load word)
다시 stack pointer를 8만큼 올려 원상태와 동일하게 만들어 주면, (addi)
메모리 입장에서도, caller 입장에서도 callee 수행 전과 동일하다고 할 수 있다.
Stack 영역
stack 영역은 프로그램이 자동으로 사용하는 임시 메모리 영역으로,
함수 호출시 생성되는 지역 변수와 매개 변수가 저장되는 영역이고, 함수 호출이 완료되면 사라진다.
stack 영역에서는 push로 데이터를 저장하고, pop으로 데이터를 인출한다.
stack 영역은 앞서 말했듯 후입선출(LIFO, Last-In First-Out)의 방식으로,
가장 나중에 들어온 데이터가 가장 먼저 인출된다.
이는 stack 영역이 메모리의 높은 주소에서 낮은 주소의 방향으로 할당되기 때문이다.
즉, 높은 주소부터 차곡차곡 낮은 주소의 방향으로 데이터가 쌓인다.
※ 컴파일 타임에 크기가 결정된다.
Heap 영역
heap 영역은 프로그래머가 직접 공간을 할당, 해제하는 메모리 영역으로,
사용자가 동적으로 할당한다.
heap 영역에서는 malloc() 또는 new 연산자를 통해 메모리를 할당하고,
free() 또는 delete 연산자를 통해 메모리를 해제한다.
heap 영역은 선입선출(FIFO, First-in First-Out)의 방식으로,
가장 먼저 들어온 데이터가 가장 먼저 인출된다.
이는 heap 영역이 메모리의 낮은 주소에서 높은 주소의 방향으로 할당되기 때문이다.
즉, 낮은 주소부터 차곡차곡 높은 주소의 방향으로 데이터가 쌓인다.
※ 런 타임에 크기가 결정된다.
Over Flow
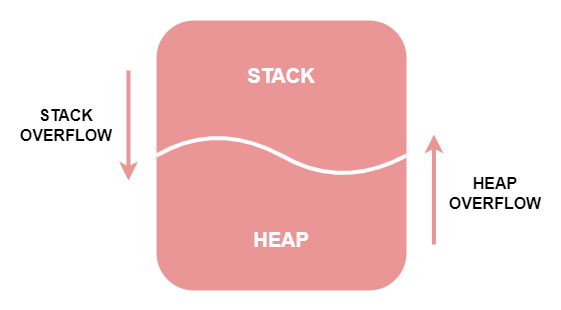
▶ 힙 오버 플로우와 스택 오버 플로우
over flow란 영어로 넘쳐 흐른다는 뜻이다.
즉, over flow는 말 그대로, 한정된 메모리 공간이 부족하여 메모리 안에 있는 데이터가 넘쳐 흐르는 현상이다.
over flow의 종류 중에는 힙 오버 플로우와 스택 오버 플로우가 있다.
stack은 메모리의 높은 주소부터 할당되고, heap은 메모리의 낮은 주소부터 할당되기 때문에,
두 영역이 확장되면서 서로의 영역을 침범할 수 있다.
이때 heap이 stack을 침범하는 경우를 heap over flow라 하고,
stack이 heap을 침범하는 경우를 stack over flow라고 한다.
Example) What is the compiled MIPS assembly code?

▶ C code
※ g: $a0, h: $a1, i: $a2, j: $a3, f: $s0
※ Suppose $s0 contains ther value of the previous procedure(caller), 즉 caller가 $s0를 사용 중이었기에, calle인 left_example가 $s0를 f를 저장하는 데에 사용하려면 먼저, $s0 값을 메모리에 저장해야 한다. (callee가 사용 굳이 안 해도 혹시 모르니 메모리에 저장해 주어야 한다)

▶ MIPS code
※ $sp를 한 칸 움직일 때 4씩 움직이는 이유는, byte addressing 때문이다. (1개의 word는 4 byte 차지)
※ $ra는 leaf_example을 calling한 caller 함수의 address가 담겨 있다. (return할 함수의 address가 담겨 있음)
컴퓨터 구조 입장에선, leaf_example 함수(callee)를 호출한 하나의 caller 함수가 있다고 생각한다.
즉, caller가 leaf_example 함수에 g, h, i, j 인수를 넘겨 주고, (argument register)
leaf_example 함수는 return value를 caller에 넘겨주면 된다. (return register)
Nested Procedures
Nested Procedures
nested (recursive, 중첩, 재귀) procedure는 argument register (ex) $a0) 사용과 return address($ra)의 충돌이 있다.

▶ Nested Procedures
caller 함수가 recursive 함수를 int n 인자를 넘겨 호출하고, 이렇게 넘겨진 n은 argument register (ex) $a0)로 전달된다.
이때 recursive 함수이기에, 호출 시마다 $a0 값이 매번 바뀌어야 한다.
하지만 하나의 레지스터 값이 계속 바뀌면 내려갔다 올라올 때 값이 없어진다. (conflict)
이를 해결하기 위해 n 값에 관계없이 함수 1개만 compiler하고, n은 메모리 stack에 저장한다.
마찬가지로, return address도 경우에 따라 자기 자신으로, 혹은 caller 돌아가야 한다. (conflict)
이 역시, 마찬가지로 메모리 stack에 return address를 저장함으로써 해결한다.
Solution
nested procedure에서는 $a0랑 return address를 모두 메모리 stack에 저장해야 한다.
Example) What is the compiled MIPS assembly code?

▶ C code
※ Suppose n: $a0
만약 n이 3이면,
caller -> f(3) -> f(2) -> f(1) -> f(0) -> f(1) -> f(2) -> f(3) -> caller 순으로 내려갔다 올라온다.

▶ MIPS code
※ $ra, $a0 중 저장 순서는 상관 없지만 stack은 위에서부터 아래로 쌓이기에 4($sp) -> 0($sp) 순서로 저장해 주어야 한다. 즉, push는 4 -> 0 순으로 하고, 반대인 pop은 0 -> 4 순으로 한다.
callee 함수로 진입한 이후에는 저장해야 할 값을 먼저 저장해 주고 if문을 실행해 주면 된다.
이때 '초록색 -> 파랑색 -> 노랑색'가 if 조건 만족할 때까지 반복하는데,
재귀 반복으로 fact로 다시 돌아갈 때, 그 다음 명령어 주소를 linkig, 즉 $ra에 다음 명령어 주소를 담는다. (연두색 주소 담음)
이때 파랑색에서 if 조건을 만족하면 L1으로 가지 않고 return을 준비한다. (보라색으로 감)
fact(n - 1)은 아직 계산이 되지 않았기에 값을 곱할 수 없어, n - 1을 먼저 계산한 후, fact로 들어가 이 값을 찾아와야 한다.
즉, 호출 전 n - 1을 먼저 해주어야 한다.
return은 return value 레지스터로 해야 하기에 addi를 통해 $v0에 return값인 1을 넣는다.
그리고 어차피 callee가 더 이상 없고 return 해주며 caller로 올라갈 것이라 $ra와 $a0는 저장할 필요가 없기에,
$sp를 두 칸 올려 $ra와 $a0를 쓰레기값으로 인식하도록 하여 버리고 이전 함수로 돌아갈 $ra와 n을 꺼낼 준비를 한다.
쉽게 말해, 초록색은 파란색을 통해 L1으로 갈 줄 알고 값을 스택 포인터를 두 칸 내려 $a0와 $ra를 저장한 것인데,
조건에 의해 L1으로 가지 않았기에 $sp를 두 칸 올려 저 두 값을 버리도록 하는 것이다.
그리고 그후, 아까 돌아갈 address를 담아놓은 곳으로 돌아 간다. (연두색으로 돌아 감)
이전 함수로 돌아가기 위해 이전 함수의 $ra와 n을 꺼내고,
mul 이용해 $v0에 계속 return값을 누적한다. ('연두색 -> 갈색' 반복)
이때, $ra가 자기 자신이 아니라 caller address가 될 때까지 반복한다. (callee 탈출)
※ mul instruction은 존재하지 않지만 곱하기 인스터럭션이 있다고 가정한 것이다.
instruction
slt rd, rs, rt // set less than, rs가 rt보다 작으면 rd를 1로, 그렇지 않으면 0으로 세팅▶ slt
beq rs rt, label // rs와 rt가 같으면 특정 레이블로 branch(분기) (뺄셈해서 0인지 확인해서 비교)▶ beq
jal target // jump and link, 그냥 jump와 달리 link를 함으로써, jump로 가긴 가지만 다시 돌아올 수 있게 함▶ jal
jr rs // jump register ($ra 주소로 감)▶ jr
Branch의 종류
1. Conditional branch
ex) beq, bne
2. Unconditional branch
ex) j, jal, jr
이때, Unconditional branch는 conditional branch 방법보다 더 멀리 점프가 가능하다.
Allocating Space for New Data on the Stack
Stack
To store the local variables of procedure, 위에서 아래로 쌓는 grow down 방식이다.
1. Frame pointer ($fp)
$sp가 가리키는 값(frame)의 시작 위치를 가리키며 (first word),
memory-references 역할을 한다.
또한, $sp가 frame을 넘어가지 않도록 막는 역할도 한다.
2. Stack pointer ($sp)
가장 최근에 저장한 값의 위치를 가리킨다.
때문에, 저장되는 값을 채우거나 (push), 값을 꺼낼 때 (pop), $sp 값은 변한다.
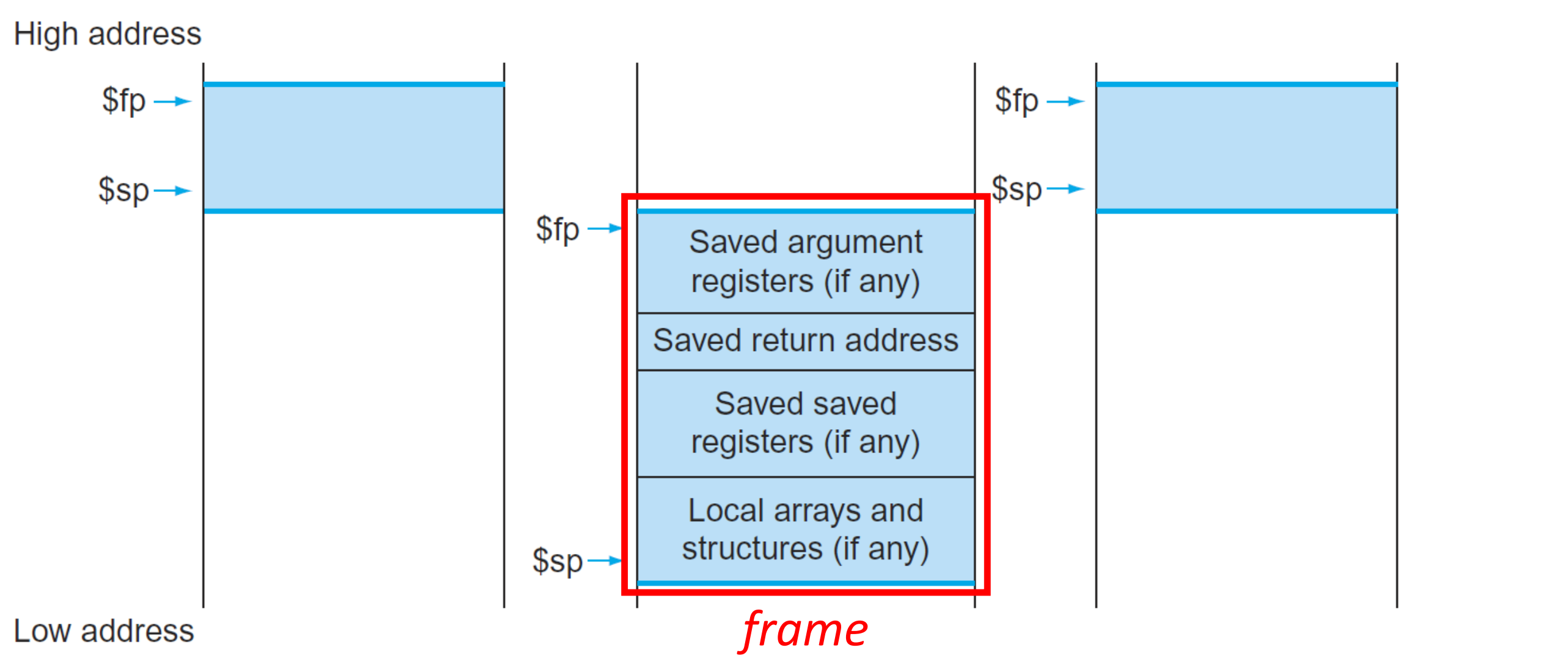
▶ Stack - $fp, $sp
Allocating Space for New Data on the Heap
Heap
To dynamically store the variables of procedure, 밑에서부터 위로 쌓는 방식이다.
이때 tack과 반대 방향으로 쌓는 이유는, 다른 특성의 데이터를 최대한 멀리 떨어뜨리기 위해서이다.
※ C code: malloc() and free() – they allocate the dynamic space on the heap (memory allocation)

▶ Heap
3. Global pointer ($gp)
static data(정적 변수)를 다룰 때 함수 내에서 쓸 수 있는 변수로,
동적인 stack, dynamic data와 달리, static data는 공간이 정해져 있다.
이때, gp는 static data의 위치의 중앙 위치를 가리킨다.
※ pc: program counter, 0 또는 1로 이루어진 instruction도 메모리에 저장되어야 하는데, 이때 instruction이 저장되어 있는 공간을 PC라고 한다. (C 언어 담긴 공간)
MIPS Addressing for 32-bit Immediate and Address
32-bit Immediate Operands

▶ Remind I-Format
표현하고자 하는 비트가 32 bits인데 실을 수 있는 constant는 16 bits씩이니 어떻게 32bits 표현?
결론적으로, 2개씩 끊어 표현하면 된다.
Step 1
Load upper immediate (lui): To set the upper 16-bits (17~32 bits) of a constant in a register
Step 2
Or immediate (ori): To insert the lower 16-bits (1~16 bits) of a constant in a register

▶ lui, ori
명령어
1. lui (load upper immediate): upper bit에 immediate값을 load 한다.
ex) lui $0, 61: 상위 16비트에 61이란 숫자를 load 한다.
2. ori (or immediate): immediate값과 or 연산을 수행한다.
ex) ori $s1, $0, 2304: 2304를 2진수로 변환한 값을 $s0와 or 연산을 하여 $s1에 저장한다.
32-bit Immediate Operands - Example

▶ Example
Step 1

▶ Step 1 -> 61
lui 명령어는 MSB로부터 16bits를 상수값으로 채운다.
Step 2

▶ Step 2 -> 2304
61과 0을 or 연산 해주면 앞부분이 61, 0과 2304를 or 연산 해주면 뒷부분이 2304가 된다.
결과적으로 lui, ori를 통해 32bits를 얻을 수 있다.
※ 이때, 0으로 초기화 되어있다는 가정이 필요한데, 왜냐면 or 연산은 하나라도 1이면 1이 되기 때문이다.
Addressing in Branches and Jumps
1. Branch (I-Format)

▶ I-Format
※ 여기선 constant가 아니라 address 값을 의미한다.
Branch
- Branch equal (Beq): check if rs and rt are equal
- Branch not equal (Bne): check if rs and rt are not equal
이러한 branch addressing 형태를 PC-relative addressing이라고 한다.
PC-relative addressing
- Program counter (PC): 현재 instrunction이 실행되는 위치 (주소값)

▶ PC-relative addressing
beq, bne를 보면 조건이 맞으면 주소로 이동하는데,
이 조건을 확인하는 시점에서 PC 값은 CPU가 명령 해석하기 전에 이미 다음으로 넘어가 있다.
즉, branch를 해야 한다는 걸 알아차린 시점이 'PC + 4'이다.
때문에 그냥 'PC'가 아니라, 'PC + 4'인 것이다. (byte addressing)
이때 Offset은 이동할 값, 즉 몇 칸을 이동할지를 나타내는 값이다. (byte addressing)
※ instruction도 instruction memory에 저장되어야 한다.
2. Jump (J-FORMAT)

▶ J-Format
Jump
- Jump: Jump to the address
Pseudo direct addressing
- Addressing method for jump

▶ Pseudo direct addressing
이 방법은 현재 PC값으로부터 얼마만큼 이동할 것인지 결정하는 방법이다.
때문에, PC 주소값의 MSB부터 4자리를 끊어 앞에 붙임으로써 PC값으로부터 너무 많이 이동하지 않도록 한다.
이는 비슷한 코드끼리 근처, 즉 주변에 있도록 하기 위해서이다.
00을 뒤에 붙이는 이유는 byte addressing이기에 4의 배수를 만들어주기 위해서이다.
그래서 결과적으로 32bits가 완성된다.

▶ Jump Example
j와 jal은 pseudo direct addressing 기법을 사용하고, jr은 단순히 return address register의 값을 넣는다.
Program counter (PC)
It contains the address of the current instruction (beq, bne)
증가된 PC, 즉 다음 instruction을 조기에 가르킨다.

▶ Program counter (PC)
bne와 Exit는 3칸 떨어져 있는데, address가 3이 아니라 2인 이유는,
PC 값이 이미 밑으로 한 칸 내려가 'PC + 4'가 되었기 때문이다.
즉, Offset이 각각 2, 20000인 것이고, 이때 byte addressing이기에 이 값들에 각각 4씩 나중에 곱해진다.
때문에 Loop의 address인 80000으로 갈 때, 80000이 아니라 20000을 적어준다.
MIPS Addressing Mode Summary
1. Immediate addressing
ex) addi

▶ Immediate addressing
2. Register addressing
(R-format)

▶ Register addressing
3. Base addressing
ex) lw, sw

▶ Base addressing
lw $s0 0($s1)▶ Base addressing example
Base addressing은 base address (ex) $s1)로부터 얼만큼 (ex) 0, offset 값) 떨어졌는지를 나타낸다.
※ 이때 Register에는 Base address의 값이 들어있다.
4. PC-relative addressing
ex) bne, beq

▶ PC-relative addressing
PC로부터 얼마나 이동할 것인지를 나타낸다. (offset)
5. Pseudo direct addressing
ex) j, jal

▶ Pseudo addressing
※ ':'은 끊어서 가져온다는 의미이다.
참고자료
https://all-young.tistory.com/17
메모리의 구조 (코드, 데이터, 힙, 스택 영역)
목차 메모리 코드(code) 영역 데이터(data) 영역 힙(heap) 영역 스택(stack) 영역 오버 플로우 메모리 위 그림과 같이, 프로그램이 실행되기 위해서는 운영체제(OS)가 프로그램의 정보를 메모리에 로드
all-young.tistory.com
[컴퓨터구조] #6. MIPS 명령어(6)
Lec 6. MIPS Instructions_6 (Language of the Computer) - Why Branch? : non-sequential flow, condition에 따른 decision 가능, 함수 호출/리턴 가능, loop (if-else, case, for, while) -> 조건에 따라, 순차적으로 갈 지/분기할 지 결정
ezeun.tistory.com
'CS > 컴퓨터구조' 카테고리의 다른 글
| Lecture 08: Instructions - Language of the Computer - 5 (5) | 2024.10.14 |
|---|---|
| Lecture 07: Instructions - Language of the Computer - 4 (1) | 2024.10.14 |
| Lecture 05: Instructions - Language of the Computer - 2 (3) | 2024.09.29 |
| Lecture 04: Instructions - Language of the Computer - 1 (6) | 2024.09.28 |
| Lecture 03: Computer Abstractions and Technology - 2 (8) | 2024.09.26 |