DreamHack의 System Hacking 로드맵을 기반으로 정리한 글입니다.
Computer Architecture
폰 노이만 구조
폰 노이만은 컴퓨터에 연산, 제어, 저장의 세 가지 핵심 기능이 필요하다고 생각했다.
근대의 컴퓨터는 연산과 제어를 위해 중앙처리장치(Central Processing Unit, CPU)를, 저장을 위해 기억장치(memory)를 사용한다. 그리고 장치 간에 데이터나 제어 신호를 교환할 수 있도록 버스(bus)라는 전자 통로를 사용한다.

▶ 폰 노이만 구조
중앙처리장치
CPU는 프로그램의 연산을 처리하고 시스템을 관리하는 컴퓨터의 두뇌이다.
프로세스의 코드를 불러오고, 실행하고, 결과를 저장하는 일련의 모든 과정이 CPU에서 일어난다.
CPU는 산술/논리 연산을 처리하는 산술논리장치(Arithmetic Logic Unit, ALU)와 CPU를 제어하는 제어장치(Control Unit), CPU에 필요한 데이터를 저장하는 레지스터(Register) 등으로 구성된다.
기억장치
기억장치는 컴퓨터가 동작하는데 필요한 여러 데이터를 저장하기 위해 사용되며, 용도에 따라 주기억장치와 보조기억장치로 분류된다.
주기억장치는 프로그램 실행 과정에서 필요한 데이터들을 임시로 저장하기 위해 사용되며, 대표적으로 램(Random-Access Memory, RAM)이 있다. 이와 반대로 보조기억장치는 운영체제, 프로그램 등과 가타이 데이터를 장기간 보관하고자 할 때 사용된다. 대표적으로 하드 드라이브(Hard Disk Drive, HDD), SSD(Solid State Drive)가 있다.
※ 기억장치가 있음에도 불구하고 CPU는 병목현상 발생을 막기 위해, 내부에 레지스터와 캐시라는 저장장치를 갖고 있다.
버스
버스는 컴퓨터 부품과 부품 사이 또는 컴퓨터와 컴퓨터 사이에 신호를 전송하는 통로를 말한다.
대표적으로 데이터가 이동하는 데이터 버스(Data Bus), 주소를 지정하는 주소 버스(Address Bus), 읽기/쓰기를 제어하는 제어 버스(Control Bus)가 있다. 이 외에도 랜선이나 데이터 전송 소프트웨어, 프로토콜 등도 버스라고 불린다.
명령어 집합 구조
명령어 집합 구조(Instruction Set Architecture, ISA)란 CPU가 해석하는 명령어의 집합을 의미한다. 프로그램은 기계어로 이루어져 있는데, 프로그램을 실행하면 이 명령어들을 CPU가 읽고, 처리한다.
ISA는 x86-64(x64), MIPS 등 다양하게 존재한다. 이렇게 다양한 ISA가 개발되고 사용되는 이유는 모든 컴퓨터가 동일한 수준의 연산 능력을 요구하지 않으며, 컴퓨팅 환경도 다양하기 때문이다.
예를 들어, x86-64는 고성능 프로세서를 설계하기 위해 사용된다. 이를 기반으로한 CPU들은 많은 전력을 소모하며, 발열도 상대적으로 심하다. 그러므로 안정적으로 전력을 공급할 수 있고, 냉각 장치를 구비하는데 공간상의 부담이 크지 않은 데스크톱 또는 랩톱(노트북)에 적합하다. 그러나 드론과 같이 배터리를 사용하거나 공유기, 인공지능 스피커처럼 크기가 작은 임베디드 기기들은 이러한 제약조건을 해결하기 어렵다. 특히 스마트폰은 피부에 닿기 때문에 발열 문제에 민감하고, 배터리로 작동하므로 고성능 프로세서를 장착하기 매우 부적합하다. 그래서 많은 임베디드 장비들은 전력 소모와 발열이 적은 MIPS 등의 프로세서를 사용하고 있다.
※ x86 기반 CPU 점유율이 압도적이다. 즉, x64 아키텍처가 가장 범용적이다. 현재 대다수 개인용 컴퓨터는 이 x86-64 아키텍처 기반의 CPU를 탑재하고 있다.
x86-64 아키텍처
n비트 아키텍처
'64비트 아키텍처', '32비트 아키텍처'에서 64와 32는 CPU가 한 번에 처리할 수 있는 데이터의 크기이다. 컴퓨터과학에서는 이를 CPU가 이해할 수 있는 데이터의 단위라는 의미에서 WORD라고 부른다. WORD의 크기는 CPU가 어떻게 설계됐느냐에 따라 달라진다. 예를 들어, 일반적인 32비트 아키텍처에서 ALU는 32비트까지 계산할 수 있음, 레지스터의 용량 및 각종 버스들의 대역폭이 32비트이다. 따라서 이들로 구성된 CPU는 설계상 32비트의 데이터까지만 처리할 수 있게 된다.
WORD가 크면 유리한 점
현대의 PC는 대부분 64비트 아키텍처의 CPU를 사용하는데, 그 이유 중 하나는 32비트 아키텍처의 CPU가 제공할 수 있는 가상 메모리의 크기가 작기 때문이다. 가상 메모리는 CPU가 프로세스에게 제공하는 가상의 메모리 공간인데, 32비트 아키텍처에서 제공하는 가상 메모리의 크기는 일상적으로 사용하기에는 적절할 수 있지만, 많은 메모리 자원을 소모하는 전문 소프트웨어나 고사양의 게임 등을 실행할 때는 부족할 수 있다.
반면 64비트 아키텍처에서 제공하는 가상 메모리의 크기는 웬만해서는 완전한 사용이 불가능할 정도로 큰 크기이기 때문에, 가용한 메모리 자원이 부족해서 소프트웨어의 최고 성능을 낼 수 없다거나 소프트웨어의 실행이 불가능한 상황은 거의 발생하지 않는다.
※ x86-64 = amd64
x86-64 아키텍처: 레지스터
레지스터는 CPU가 데이터를 빠르게 저장하고 사용할 때 이용하는 보관소이며, 산술 연산에 필요한 데이터를 저장하거나 주소를 저장하고 참조하는 등 다양한 용도로 사용된다. x64 아키텍처에는 범용 레지스터(General Register), 세그먼트 레지스터(Segment Register), 명령어 포인터 레지스터(Instruction Pointer Register, IP), 플래그 레지스터(Flag Register)가 존재한다.
범용 레지스터
범용 레지스터는 주용도는 있으나, 그 외의 다양한 용도로 사용될 수 있는 레지스터이다. x86-64에서 각각의 범용 레지스터는 8바이트를 저장할 수 있으며, 부호 없는 정수를 기준으로 2^64-1까지의 수를 나타낼 수 있다.
자주 쓰이는 범용 레지스터들의 주용도는 다음과 같다. 이 외에도 x64에는 r8, r9, ..., r15까지의 범용 레지스터가 더 존재한다.
| 이름 | 주용도 |
| rax (accumulator register) | 함수의 반환 값 |
| rbx (base register) | x64에서는 주된 용도 없음 |
| rcx (counter register) | 반복문의 반복 횟수, 각종 연산의 시행 횟수 |
| rdx (data register) | x64에서는 주된 용도 없음 |
| rsi (source index) | 데이터를 옮길 때 원본을 가리키는 포인터 |
| rdi (destination index) | 데이터를 옮길 때 목적지를 가리키는 포인터 |
| rsp (stack pointer) | 사용중인 스택의 위치를 가리키는 포인터 |
| rbp (stack base pointer) | 스택의 바닥을 가리키는 포인터 |
세그먼트 레지스터
x64 아키텍처에는 cs, ss, ds, es, fs, gs 총 6가지 세그먼트 레지스터가 존재하며, 각 레지스터의 크기는 16비트이다. 세그먼트 레지스터는 x64로 아키텍처가 확장되면서 용도에 큰 변화가 생긴 레지스터이다. 과거에는 메모리 세그멘테이션이나, 가용 메모리 공간의 확장을 위해 사용됐으나, 현재는 주로 메모리 보호를 위해 사용되는 레지스터이다.
현대의 x64에서 cs, ds, ss 레지스터는 코드 영역과 데이터, 스택 메모리 영역을 가리킬 때 사용되고, 나머지 레지스터는 운영체제 별로 용도를 결정할 수 있도록 범용적인 용도로 제작된 세그먼트 레지스터이다.
명령어 포인터 레지스터
프로그램은 일련의 기계어 코드들로 이루어져 있다. 이 중에서 CPU가 어느 부분의 코드를 실행할지 가리키는 게 명령어 포인터 레지스터의 역할이다. x64 아키텍처의 명령어 레지스터는 rip이며, 크기는 8바이트이다.
플래그 레지스터
플래그 레지스터는 프로세서의 현재 상태를 저장하고 있는 레지스터이다. x64 아키텍처에서는 RFLAGS라고 불리는 64비트 크기의 플래그 레지스터가 존재하며, 과거 16비트 플래그 레지스터가 확장된 것이다. 깃발을 올리고, 내리는 행위로 신호를 전달하듯, 플래그 레지스터는 자신을 구성하는 여러 비트들로 CPU의 현재 상태를 표현한다.
RFLAGS는 64비트이므로 최대 64개의 플래그를 사용할 수 있지만, 실제로는 20여개의 비트만 사용한다다. 그리고 그 중에서 주로 접하게 될 것들은 아래의 표와 같다.
| 플래그 | 의미 |
| CF(Carry Flag) | 부호 없는 수의 연산 결과가 비트의 범위를 넘을 경우 설정된다. |
| ZF(Zero Flag) | 연산의 결과가 0일 경우 설정된다. |
| SF(Sign Flag) | 연산의 결과가 음수일 경우 설정된다. |
| OF(Overflow Flag) | 부호 있는 수의 연산 결과가 비트 범위를 넘을 경우 설정된다. |
플래그를 사용하는 간단한 예로, 3의 값을 갖는 a와 5의 값을 갖는 b가 있을 때, a에서 b를 빼는 연산을 하면, 연산의 결과가 음수이므로 SF가 설정된다. 그러면 CPU는 SF를 통해 a가 b보다 작았음을 알 수 있다.
레지스터 호환
x86-64 아키텍처는 IA-32의 64비트 확장 아키텍처이며, 호환이 가능하다. IA-32에서 CPU의 레지스터들은 32비트 크기를 가지며, 이들의 명칭은 각각 eax, ebx, ecx, edx, esi, edi, esp, ebp이다. 호환성을 위해 이 레지스터들은 x86-64에서도 그대로 사용이 가능하다.
rax, rbx, rcx, rdx, rsi, rdi, rsp, rbp가 이들의 확장된 형태이며, eax, ebx 등은 확장된 레지스터의 하위 32비트를 가리킨다. 예를 들어, eax는 rax의 하위 32비트를 의미한다.
※ rax = 0x012345789abcdef이면, eax = 0x89abcdef, ax = 0xcdef이다. 이때 0x는 16진수임을 나타내는 것이다.
또한 마찬가지로, 과거 16비트 아키텍처인 IA-16과의 호환을 위해, ax, bs, cx, dx, si, di, sp, bp는 eax, ebx, ecx, edx, esi, edi, esp, ebp의 하위 16비트를 가리킨다.
이들 중 몇몇은 다시 상위 8비트, 하위 8비트로 나뉜다.
※ ah는 ax의 상위 8비트 al은 ax의 하위 8비트이므로 ax = 0xcdef이면, ah = 0xcd, al = 0xef이다.
Linux Memory Layout
세그먼트
리눅스에서는 프로세스의 메모리를 크게 5가지의 세그먼트(Segment)로 구분한다. 여기서 세그먼트란 적재되는 데이터의 용도별로 메모리의 구획을 나눈 것인데, 크게 코드 세그먼트, 데이터 세그먼트, BSS 세그먼트, 힙 세그먼트, 그리고 스택 세그먼트로 구분한다.

▶ 리눅스에서의 프로세스 메모리는 5개의 영역으로 구분된다.
운영체제가 메모리를 용도별로 나누면, 각 용도에 맞게 적절한 권한을 부여할 수 있다는 장점이 있다. 권한은 읽기, 쓰기, 그리고 실행이 존재하며, CPU는 메모리에 대해 권한이 부여된 행위만 할 수 있다.
예를 들어, 데이터 세그먼트에는 프로그램이 실행되면서 사용하는 데이터가 적재된다. CPU는 이곳의 데이터를 읽을 수 있어야 하며, 따라서 이 영역에는 읽기 권한이 부여된다. 반면 이 영역의 데이터는 실행 대상이 아니므로 실행 권한은 부여되지 않는다.
코드 세그먼트
코드 세그먼트(Code Segmen)는 실행 가능한 기계 코드가 위치하는 영역으로 텍스트 세그먼트(Text Segment)라고도 불린다.
프로그램이 동작하려면 코드를 실행할 수 있어야 하므로 이 세그먼트에는 읽기 권한과 실행 권한이 부여된다. 반면 쓰기 권한이 있으면 공격자가 악의적인 코드를 삽입하기가 쉬워지므로, 대부분의 현대 운영체제는 이 세그먼트에 쓰기 권한을 제거한다.
아래에서 31337을 반환하는 main 함수가 컴파일되면 554889e5b8697a00005dc3라는 기계 코드로 변환되는데, 이 기계 코드가 코드 세그먼트에 위치하게 된다.
int main() { return 31337; }
데이터 세그먼트
데이터 세그먼트에는 컴파일 시점에 값이 정해진 전역 변수 및 전역 상수들이 위치한다. CPU가 이 세그먼트의 데이터를 읽을 수 있어야 하므로, 읽기 권한이 부여된다.
※ 컴파일 과정: 전처리 -> 컴파일(고수준 언어를 저수준 언어인 기계어로 번역하는 작업) -> 어셈블리 -> 링킹, 컴파일은 이러한 과정을 통해 소스 코드를 기계어로 이루어진 실행 파일로 만든다.
데이터 세그먼트는 쓰기가 가능한 세그먼트와 쓰기가 불가능한 세그먼트로 다시 분류되는데, 쓰기가 가능한 세그먼트는 전역 변수와 같이 프로그램이 실행되면서 값이 변할 수 있는 데이터들이 위치한다. 이런 세그먼트는 data 세그먼트라고 부른다.
반면 쓰기가 불가능한 세그먼트에는 프로그램이 실행되면서 값이 변하면 안 되는 데이터들이 위치한다. 전역으로 선언된 상수가 여기에 포함된다. 이런 세그먼트를 rodata(read-only data) 세그먼트라고 부른다.
아래는 데이터 세그먼트에 포함되는 여러 데이터 유형이다. 이때 str_ptr은 "readonly"라는 문자열을 가리키고 있는데, 이 문자열은 상수 문자열로 취급되어 rodata에 위치하며, 이를 가리키는 str_ptr은 전역 변수로서 data에 위치한다.
int data_num = 31337; // data
char data_rwstr[] = "writable_data"; // data
const char data_rostr[] = "readonly_data"; // rodata
char *str_ptr = "readonly"; // str_ptr은 data, 문자열은 rodata
int main() { ... }
BSS 세그먼트
BSS 세그먼트(Block Started By Symbol Segment)는 컴파일 시점에 값이 정해지지 않은 전역 변수가 위치하는 메모리 영역이다. 여기에는 개발자가 선언만 하고 초기화하지 않은 전역 변수 등이 포함된다. 이 세그먼트의 메모리 영역은 프로그램이 시작될 때, 모두 0으로 값이 초기화된다. 이런 특성 때문에 C 코드를 작성할 때, 초기화되지 않은 전역 변수의 값은 0이 된다.
이 세그먼트에는 읽기 권한 및 쓰기 권한이 부여된다.
아래 코드에서 초기화되지 않은 전역 변수인 bss-data가 BSS 세그먼트에 위치하게 된다.
int bss_data;
int main() {
printf("%d\n", bss_data); // 0
return 0;
}
스택 세그먼트
스택 세그먼트는 프로세스의 스택이 위치하는 영역으로, 함수의 인자나 지역 변수와 같은 임시 변수들이 실행중에 저장되는 곳이다.
스택 세그먼트는 스택 프레임(Stack Frame)이라는 단위로 사용된다. 스택 프레임은 함수가 호출될 때 생성되고, 반환될 때 해제된다.
아래의 코드에서 유저가 입력한 choice에 따라 call_true()가 호출될 수도, call_false()가 호출될 수도 있다.
void func() {
int choice = 0;
scanf("%d", &choice);
if (choice)
call_true();
else
call_false();
return 0;
}
또한 프로그램의 전체 실행 흐름은 사용자의 입력을 비롯한 여러 요인에 영향을 받기에, 어떤 프로세스가 실행될 때, 이 프로세스가 얼마 만큼의 스택 프레임을 사용하게 될 지를 미리 계산하는 것은 일반적으로 불가능하다. 그래서 운영체제는 프로세스를 시작할 때 작은 크기의 스택 세그먼트를 먼저 할당해주고, 부족해질 때마다 이를 확장해준다. 스택에 대해서 '아래로 자란다'라는 표현을 종종 사용하는데, 이는 스택이 확장될 때, 기존 주소보다 낮은 주소로 확장되기 때문이다.
이 영역에는 CPU가 자유롭게 값을 읽고 쓸 수 있어야 하므로, 읽깅와 쓰기 권한이 부여된다.
위의 코드에서는 지역변수 choice가 스택에 저장된다.
힙 세그먼트
힙 세그먼트는 힙 데이터가 위치하는 세그먼트로, 스택과 마찬가질 실행 중에 동적으로 할당될 수 있으며, 리눅스에서는 스택 세그먼트와 반대 방향으로 자란다.
C언어에서 malloc(), calloc() 등을 호출해서 할당받는 메모리가 이 세그먼트에 위치하게 되며, 일반적으로 읽기와 쓰기 권한이 부여된다.
아래 예제 코드는 heap_data_ptr에 malloc()으로 동적 할당한 영역의 주소를 대입하고, 이 영역에 값을 쓴다. heap_data_ptr은 지역변수이므로 스택에 위치하며, malloc으로 할당은 힙 세그먼트의 주소를 가리킨다.
int main() {
int *heap_data_ptr =
malloc(sizeof(*heap_data_ptr)); // 동적 할당한 힙 영역의 주소를 가리킴
*heap_data_ptr = 31337; // 힙 영역에 값을 씀
printf("%d\n", *heap_data_ptr); // 힙 영역의 값을 사용함
return 0;
}
※ 힙과 스택이 메모리를 최대한 자유롭게 사용할 수 있게 함으로써 충돌 문제로부터 비교적 자유롭게 하기 위해 힙과 스택 세그먼트의 자라는 방향이 반대이다.
| 세그먼트 | 역할 | 일반적인 권한 | 사용 예 |
| 코드 세그먼트 | 실행 가능한 코드가 저장된 영역 | 읽기, 실행 | main() 등의 함수 코드 |
| 데이터 세그먼트 | 초기화된 전역 변수 또는 상수가 위치하는 영역 | 읽기와 쓰기 또는 읽기 전용 | 초기화된 전역 변수, 전역 상수 |
| BSS 세그먼트 | 초기화되지 않은 데이터가 위치하는 영역 | 읽기, 쓰기 | 초기화되지 않은 전역 변수 |
| 스택 세그먼트 | 임시 변수가 저장되는 영역 | 읽기, 쓰기 | 지역 변수, 함수의 인자 등 |
| 힙 세그먼트 | 실행 중에 동적으로 사용되는 영역 | 읽기, 쓰기 | malloc(), calloc() 등으로 할당 받은 메모리 |
▶ 세그먼트 요약
x86 Assembly
x64 어셈블리 언어
기본 구조
x64 어셈블리 언어는 동사에 해당하는 명령어(Operation Code, Opcode)와 목적어에 해당하는 피연산자(Operand)로 구성된다.

▶ x86-64 어셈블리어 문법 구조
명령어
인텔의 x64에는 매우 많은 명령어가 존재한다. 다음 표는 이 중 중요한 21개의 명령어이다.
| 명령 코드 | |
| 데이터 이동(Data Transfer) | mov, lea |
| 산술 연산(Arithmetic) | inc, dec, add, sub |
| 논리 연산(Logical) | and, or, xor, not |
| 비교(Comparison) | cmp, test |
| 분기(Branch) | jmp, je, jg |
| 스택(Stack) | push, pop |
| 프로시져(Procedure) | call, ret, leave |
| 시스템 콜(System call) | syscall |
피연산자
피연산자에는 총 3가지 종류가 있다.
- 상수(Immediate Value)
- 레지스터(Register)
- 메모리(Memory)
메모리 피연산자는 []으로 둘러싸인 것으로 표현되며, 앞에 크기 지정자(Size Directive) TYPE PTR(포인터)이 추가될 수 있다. 여기서 타입에는 BYTE, WORD, DWORD, QWORD가 올 수 있으며, 각각 1바이트, 2바이트, 4바이트, 8바이트의 크기를 지정한다.
아래 표는 메모리 피연산자의 예시이다.
| 메모리 피연산자 | |
| QWORD PTR [0x8048000] | 0x8048000의 데이터를 8바이트만큼 참조 |
| DWORD PTR [0x8048000] | 0x8048000의 데이터를 4바이트만큼 참조 |
| WORD PTR [rax] | rax가 가르키는 주소에서 데이터를 2바이트만큼 참조 |
x86-64 어셈블리 명령어: 데이터 이동
데이터 이동 명령어는 어떤 값을 레지스터나 메모리에 옮기도록 지시한다.
move
|
mov dst, src: src에 들어있는 값을 dst에 대입 (dst에 '값' 저장)
|
|
|
mov rdi, rsi
|
rsi의 값을 rdi에 대입
|
|
mov QWORD PTR[rdi], rsi
|
rsi의 값을 rdi가 가리키는 주소에 대입
|
|
mov QWORD PTR[rdi+8*rcx], rsi
|
rsi의 값을 rdi+8*rcx가 가리키는 주소에 대입
|
lea
|
lea dst, src: src의 유효 주소(Effective Address, EA)를 dst에 저장 (dst에 '주소' 저장)
|
|
|
lea rsi, [rbx+8*rcx]
|
rbx+8*rcx 를 rsi에 대입
|
※ lea: load effective address
x86-64 어셈블리 명령어: 산술 연산
산술 연산 명령어는 덧셈, 뺄셈, 곱셈, 나눗셈 연산을 지시한다.
add
|
add dst, src: dst에 src의 값을 더함
|
|
|
add eax, 3
|
eax += 3
|
|
add ax, WORD PTR[rdi]
|
ax += *(WORD *)rdi
|
|
sub dst, src: dst에서 src의 값을 뺌
|
|
|
sub eax, 3
|
eax -= 3
|
|
sub ax, WORD PTR[rdi]
|
ax -= *(WORD *)rdi
|
inc
|
inc op: op의 값을 1 증가시킴
|
|
|
inc eax
|
eax += 1
|
dec
|
dec op: op의 값을 1 감소시킴
|
|
|
dec eax
|
eax -= 1
|
x86-64 어셈블리 명령어: 논리 연산
논리 연산 명령어는 and, or, xor, not을 지시한다. 이 연산은 비트 단위로 이루어진다.
and
[Register]
eax = 0xffff0000
ebx = 0xcafebabe
[Code]
and eax, ebx
[Result]
eax = 0xcafe0000▶ and dst, src: dst와 src의 비트가 모두 1이면 1, 아니면 0

▶ and 풀이
or
[Register]
eax = 0xffff0000
ebx = 0xcafebabe
[Code]
or eax, ebx
[Result]
eax = 0xffffbabe▶ or dst, src: dst와 src의 비트 중 하나라도 1이면 1, 아니면 0
xor
[Register]
eax = 0xffffffff
ebx = 0xcafebabe
[Code]
xor eax, ebx
[Result]
eax = 0x35014541▶ xor dst, src: dst와 src의 비트가 서로 다르면 1, 같으면 0
not
[Register]
eax = 0xffffffff
[Code]
not eax
[Result]
eax = 0x00000000▶ not op: op의 비트 전부 반전
x86-64 어셈블리 명령어:비교
비교 명령어는 두 피연산자의 값을 비교하고, 플래그를 설정한다.
cmp
[Code]
1: mov rax, 0xA
2: mov rbx, 0xA
3: cmp rax, rbx ; ZF=1▶ cmp op1, op2: op1과 op2를 비교
cmp(compare)는 두 피연산자를 빼서 대소를 비교하며, 이때 연산의 결과는 op1에 대입하지 않는다.
예를 들어, 서로 같은 두 수를 빼면 결과가 0이 되어 ZF 플래그가 설정되는데, 이후에 CPU는 이 플래그를 보고 두 값이 같았는지 판단할 수 있다.
test
[Code]
1: xor rax, rax // rax⊕rax=0
2: test rax, rax ; ZF=1▶ test op1, op2: op1과 op2를 비교
test는 두 피연산자에 AND 비트 연산을 취하며, 이때 연산의 결과는 op1에 대입하지 않는다.
예를 들어, 위 코드처럼 0이 된 rax를 op1과 op2로 삼아 test를 수행하면, 결과가 0이므로 ZF 플래그가 설정된다. 이후에 CPU는 이 플래그를 보고 rax가 0이었는지 판단할 수 있다.
x86-64 어셈블리 명령어: 분기
분기 명령어는 rip(명령어 레지스터)를 이동시켜 실행 흐름을 바꾼다.
jmp
[Code]
1: xor rax, rax
2: jmp 1 ; jump to 1▶ jmp addr: addr로 rip를 이동시킴
je
[Code]
1: mov rax, 0xcafebabe
2: mov rbx, 0xcafebabe
3: cmp rax, rbx ; rax == rbx
4: je 1 ; jump to 1▶ je addr: 직전에 비교한 두 피연산자가 같으면 점프 (jump if equal)
jg
[Code]
1: mov rax, 0x31337
2: mov rbx, 0x13337
3: cmp rax, rbx ; rax > rbx
4: jg 1 ; jump to 1▶ jg addr: 직전에 비교한 두 연산자 중 전자가 더 크면 점프 (jump if greater)
x86-64 어셈블리 명령어: 스택
x64 아키텍처에서는 push, pop의 명령어로 스택을 조작할 수 있다.
push
push val: val을 스택 최상단에 쌓음
스택은 메모리의 하향 성장 구조를 가지므로, push는 rsp가 감소한다.
rsp -= 8
[rsp] = val▶ 연산
[Register]
rsp = 0x7fffffffc400
[Stack]
0x7fffffffc400 | 0x0 <- rsp
0x7fffffffc408 | 0x0
[Code]
push 0x31337▶ 예제
[Register]
rsp = 0x7fffffffc3f8
[Stack]
0x7fffffffc3f8 | 0x31337 <- rsp
0x7fffffffc400 | 0x0
0x7fffffffc408 | 0x0▶ 결과
pop
pop reg: 스택 최상단의 값을 꺼내서 reg(register)에 대입
스택은 메모리의 하향 성장 구조를 가지므로, pop은 rsp가 증가한다.
rsp += 8
reg = [rsp-8]▶ 연산
[Register]
rax = 0
rsp = 0x7fffffffc3f8
[Stack]
0x7fffffffc3f8 | 0x31337 <- rsp
0x7fffffffc400 | 0x0
0x7fffffffc408 | 0x0
[Code]
pop rax▶ 예제
[Register]
rax = 0x31337
rsp = 0x7fffffffc400
[Stack]
0x7fffffffc400 | 0x0 <- rsp
0x7fffffffc408 | 0x0▶ 결과
📌 x86-64 어셈블리 명령어: 프로시저
컴퓨터 과학에서 프로시저(Procedure)는 특정 기능을 수행하는 코드 조각을 말한다. 프로시저를 사용하면 반복되는 연산을 프로시저 호출로 대체할 수 있어서 전체 코드의 크기를 줄일 수 있으며, 기능별로 코드 조각에 이름을 붙일 수 있게 되어 코드의 가독성을 크게 높일 수 있다.
프로시저를 부르는 행위를 호출(Call)이라고 부르며, 프로시저에서 돌아오는 것을 반환(Return)이라고 부른다. 프로시저를 호출할 때는 프로시저를 실행하고 나서 원래의 실행 흐름으로 돌아와야 하므로, call 다음의 명령어 주소(Return Address, 반환 주소)를 스택에 저장하고 프로시저로 rip을 이동시킨다.
x64 어셈블리 언어에는 프로시저의 호출과 반환을 위한 call, leave, ret 명령어가 있다.
call
call addr: addr에 위치한 프로시저 호출
push return_address
jmp addr▶ 연산
[Register]
rip = 0x400000
rsp = 0x7fffffffc400
[Stack]
0x7fffffffc3f8 | 0x0
0x7fffffffc400 | 0x0 <- rsp
[Code]
0x400000 | call 0x401000 <- rip
0x400005 | mov esi, eax
...
0x401000 | push rbp▶ 예제
[Register]
rip = 0x401000
rsp = 0x7fffffffc3f8
[Stack]
0x7fffffffc3f8 | 0x400005 <- rsp
0x7fffffffc400 | 0x0
[Code]
0x400000 | call 0x401000
0x400005 | mov esi, eax
...
0x401000 | push rbp <- rip▶ 결과
leave
leave: 스택 프레임 정리
※ 함수별로 서로가 사용하는 스택의 영역을 명확히 구분하기 위해 스택 프레임이 사용된다. 대부분의 Application binary interface(ABI)에서 함수는 호출될 때 자신의 스택 프레임을 만들고, 반환할 때 이를 정리한다.
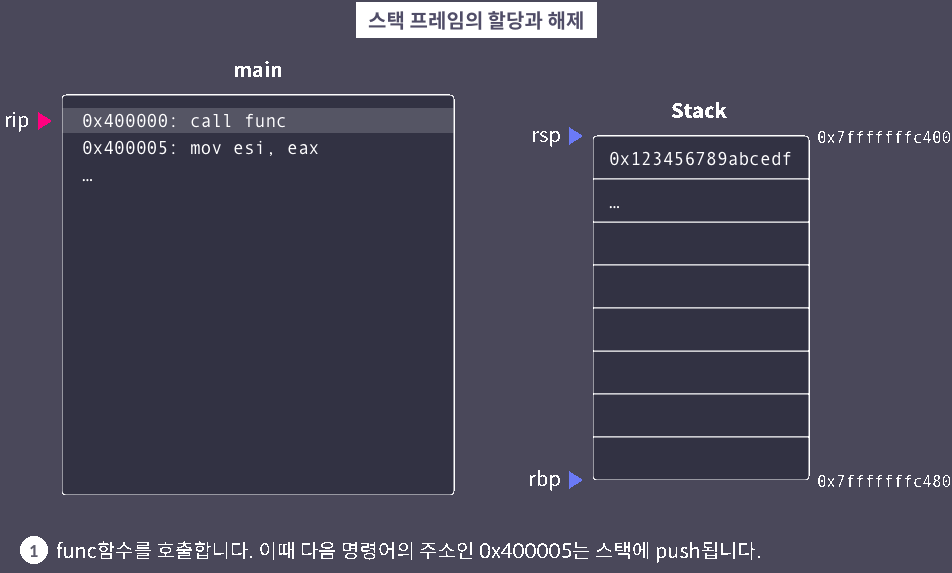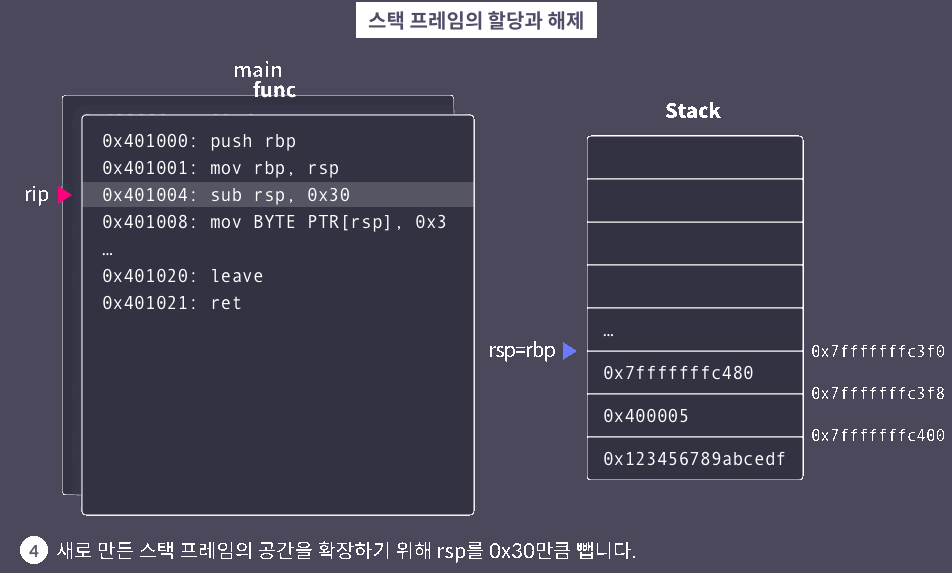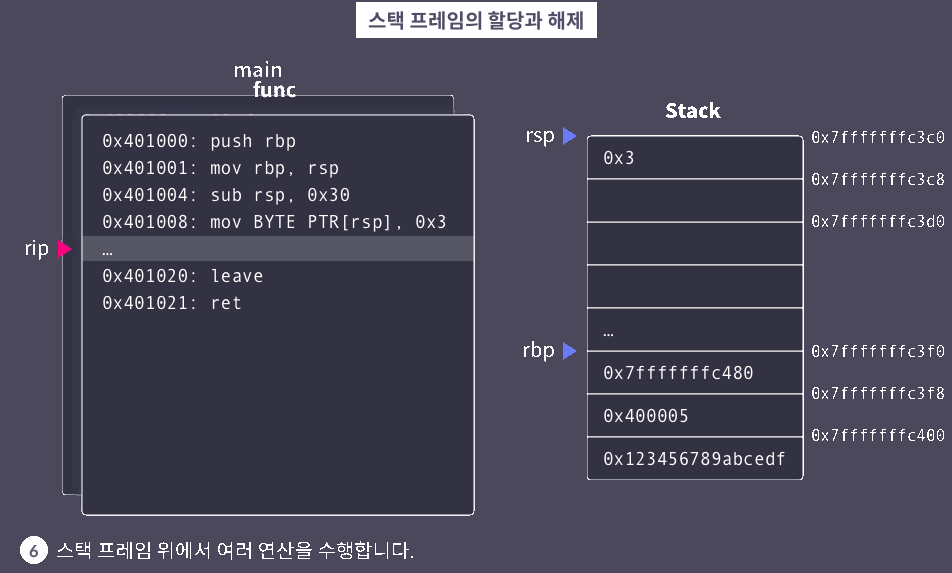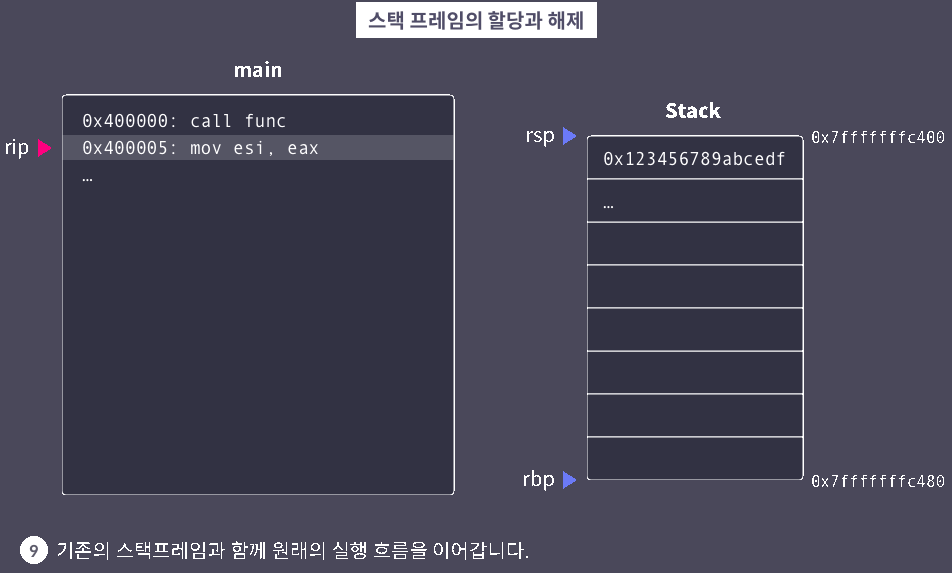
▶ 스택 프레임 시각화
mov rsp, rbp
pop rbp▶ 연산
[Register]
rsp = 0x7fffffffc400
rbp = 0x7fffffffc480
[Stack]
0x7fffffffc400 | 0x0 <- rsp
...
0x7fffffffc480 | 0x7fffffffc500 <- rbp
0x7fffffffc488 | 0x31337
[Code]
leave▶ 예제
[Register]
rsp = 0x7fffffffc488
rbp = 0x7fffffffc500
[Stack]
0x7fffffffc400 | 0x0
...
0x7fffffffc480 | 0x7fffffffc500
0x7fffffffc488 | 0x31337 <- rsp
...
0x7fffffffc500 | 0x7fffffffc550 <- rbp▶ 결과
ret
ret: return address로 반환
ret은 호출자의 실행 흐름으로 돌아간다.
pop rip▶ 연산
[Register]
rip = 0x401008
rsp = 0x7fffffffc3f8
[Stack]
0x7fffffffc3f8 | 0x400005 <- rsp
0x7fffffffc400 | 0
[Code]
0x400000 | call 0x401000
0x400005 | mov esi, eax
...
0x401000 | mov rbp, rsp
...
0x401007 | leave
0x401008 | ret <- rip▶ 예제
[Register]
rip = 0x400005
rsp = 0x7fffffffc400
[Stack]
0x7fffffffc3f8 | 0x400005
0x7fffffffc400 | 0x0 <- rsp
[Code]
0x400000 | call 0x401000
0x400005 | mov esi, eax <- rip
...
0x401000 | mov rbp, rsp
...
0x401007 | leave
0x401008 | ret▶ 결과
📌 x86-64 어셈블리 명령어: 시스템 콜
윈도우, 리눅스, 맥 등의 현대 운영체제는 컴퓨터 자원의 효율적인 사용을 위해, 그리고 사용자에게 편리한 경험을 제공하기 위해, 내부적으로 매우 복잡한 동작을 한다. 운영체제는 연결된 모든 하드웨어 및 소프트웨어에 접근할 수 있으며, 이들ㅇ르 제어할 수도 있다. 그리고 해킹으로부터 이 막강한 권한을 보호하기 위해 커널 모드와 유저 모드로 권한을 나눈다.
1. 커널모드는 운영체제가 전체 시스템을 제어하기 위해 시스템 소프트웨어에 부여하는 권한이다. 파일 시스템, 입력/출력, 네트워크 통신, 메모리 관리 등 모든 저수준 작업은 사용자 모르게 커널 모드에서 진행된다. 커널 모드에서는 시스템의 모든 부분을 제어할 수 있기 때문에, 해커가 커널 모드까지 진입하게 되면 시스템은 거의 무방비 상태가 된다.
2. 유저 모드는 운영체제가 사용자에게 부여하는 권한이다. 브라우저를 이용하여 드림핵을 보거나, 유튜브를 시청하는 것, 게임을 하고 프로그래밍을 하는 것 등은 모두 유저 모드에서 이루어진다. 리눅스에서 루트 권한으로 사용자를 추가하고, 패키지를 내려 받는 행위 등도 마찬가지이다. 유저 모드에서는 해킹이 발생해도, 해커가 유저 모드의 권한까지 밖에 획득하지 못하기 때문에 해커로부터 커널의 막강한 권한을 보호할 수 있다.
시스템 콜(system call, syscall)은 유저 모드에서 커널 모드의 시스템 소프트웨어에게 어떤 동작을 요청하기 위해 사용된다. 소프트웨어 대부분은 커널의 도움이 필요하다. 예를 들어, 사용자가 cat flag를 실행하면, cat은 flag라는 파일을 읽어서 사용자의 화면에 출력해 주어야 한다. 그런데 flag는 파일 시스템에 존재하므로 이를 읽으려면 파일 시스템에 접근할 수 있어야 한다. 유저 모드에서는 이를 직접할 수 없으므로 커널이 도움을 주어야 한다. 여기서, 도움이 필요하다는 요청을 시스템 콜이라고 한다. 유저 모드의 소프트웨어가 필요한 도움을 요청하면, 커널이 요청한 동작을 수행하여 유저에게 결과를 반환한다.
syscall
x64 아키텍처에서는 시스템콜을 위해 syscall 명령어가 있다.
요청: rax
인자 순서: rdi -> rsi -> rdx -> rcx -> r8 -> r9 -> stack▶ 요청 / 인자 순서
[Register]
rax = 0x1
rdi = 0x1
rsi = 0x401000
rdx = 0xb
[Memory]
0x401000 | "Hello Wo"
0x401008 | "rld"
[Code]
syscall▶ 예제
Hello World▶ 결과
아래의 syscall table을 보면, rax가 0x1일 때, 커널에 write 시스템콜을 요청한다. 이때 rdi, rsi, rdx가 0x1, 0x401000, 0xb 이므로 커널은 write(0x1, 0x401000, 0xb)를 수행하게 된다.
write함수의 각 인자는 출력 스트림, 출력 버퍼, 출력 길이를 나타낸다. 여기서 0x1은 stdout이며, 이는 일반적으로 화면을 의미한다. 0x401000에는 Hello World가 저장되어 있고, 길이는 0xb로 지정되어 있으므로, 화면에 Hello World가 출력된다.
|
syscall
|
rax
|
arg0 (rdi)
|
arg1 (rsi)
|
arg2 (rdx)
|
|
read
|
0x00
|
unsigned int fd
|
char *buf
|
size_t count
|
|
write
|
0x01
|
unsigned int fd
|
const char *buf
|
size_t count
|
|
open
|
0x02
|
const char *filename
|
int flags
|
umode_t mode
|
|
close
|
0x03
|
unsigned int fd
|
|
|
|
mprotect
|
0x0a
|
unsigned long start
|
size_t len
|
unsigned long prot
|
|
connect
|
0x2a
|
int sockfd
|
struct sockaddr * addr
|
int addrlen
|
|
execve
|
0x3b
|
const char *filename
|
const char *const *argv
|
const char *const *envp
|
▶ x64 syscall 테이블의 일부
참고자료
https://jjeongsu.tistory.com/6
Background: x86 Assembly Essential Part(1) 어셈블리 명령어
어셈블리어 기본 구조 어셈블리어는 명령어와 피연산자로 이루어져 있다. 주로 어셈블리어의 형식은 [명령어] [피연산자]이다. 주요 명령어는 다음과 같다 데이터 이동(Data Transfer) mov, lea 산술
jjeongsu.tistory.com
📌 https://jjeongsu.tistory.com/8
Quiz: x86 Assembly 1
문제: end로 점프하면 프로그램이 종료된다고 가정하자. 프로그램이 종료됐을 때, 0x400000 부터 0x400019까지의 데이터를 대응되는 아스키 문자로 변환하면 어느 문자열이 나오는가? [Register] rcx = 0 rd
jjeongsu.tistory.com
📌 https://jjeongsu.tistory.com/9
Quiz: x86 Assembly 2
문제: 다음 어셈블리 코드를 실행했을 때 출력되는 결과로 올바른 것은? [Code] main: push rbp mov rbp, rsp mov esi, 0xf mov rdi, 0x400500 call 0x400497 mov eax, 0x0 pop rbp ret write_n: push rbp mov rbp, rsp mov QWORD PTR [rbp-0x8],
jjeongsu.tistory.com
'Security > System Hacking' 카테고리의 다른 글
| Beginners: DH101 - 1 (컴퓨터 과학 기초) (3) | 2025.02.06 |
|---|---|
| System Hacking: Shellcode - 2 (1) | 2025.02.01 |
| System Hacking: Shellcode - 1 (3) | 2025.01.23 |
| System Hacking: Tool Installation - 2 (0) | 2025.01.21 |
| System Hacking: Tool Installation - 1 (0) | 2025.01.20 |