경희대학교 장대희 교수님의 정보보호 수업을 기반으로 정리한 글입니다.
DNS와 hosts 파일
인터넷에 대한 프로토콜이 다양하게 있는데, 그중에 보안과 연관성이 많은 대표적인 것이 바로 DNS이다.
hosts 파일을 이용한 정보 수집
Hosts 파일
DNS 프로토콜을 처리하기 위한 방법론엔 세 가지가 있다. 실제로 서버와 패킷이 왔다갔다 하며 IP를 해석하는 것, 혹은 한 번 알아낸 IP 주소를 캐싱 하거나, 따로 매우 자주 사용하는 도메인의 경우엔 아예 하드코딩하여 지정하는 방법이 있다. 이때 hosts 파일이라는 게 결국 DNS의 가장 기초적인 것 중 하나인 하드코딩에 해당한다.
매번 domain의 ip 주소를 해석해야 하면 성능이 느려지고 부하가 많아지니, 어차피 바뀔 일 없는 그런 도메인 서버 하나에 고정 ip 주소 하나 박힌 사이트가 있으면, 그 사이트의 ip 주소를 내 컴퓨터의 hosts 파일에 하드코딩해서 기억해 놓고 DNS 프로토콜을 아예 시작도 안 할 수 있다.
hosts 파일은 리눅스에도 있고, 윈도우에도 있고, 일반적은 OS에도 전부 있다.
- 윈도우 계열 시스템: [윈도우 설치 디렉터리] \ windows \ system32 \ drivers \ etc \ host,
- 리눅스: [root 디렉터리]/etc/hosts가 이에 해당

▶ hosts 파일의 예 (windows)

▶ hosts 파일의 기본 구조
hosts 파일은 보통 잘 쓰이지 않고, localhost 127.0.0.1과 같은 해석이 사실상 필요없는 특수한 IP 주소를 대상으로 사용한다.
즉, 인터넷 망이 아니라 인터넷이 필요없는 특수한 경우에 보통 사용한다.
특수한 경우에 사용하지만 기본적으로 활성화되어 있어, hosts 파일 안에 데이터가 써지면 OS가 기본적으로 사용한다.
[실습] hosts 파일을 이용해 이름 해석하기
1. 도메인 등록하기

▶ ping www.hanbit.co.kr

▶ [원하는 IP 주소] www.hanbit.co.kr hanbit
그 이후, 다시 ping을 때리면 [원하는 IP 주소]로 바뀐 걸 확인 할 수 있다.
2. hosts 파일 동작 확인하기
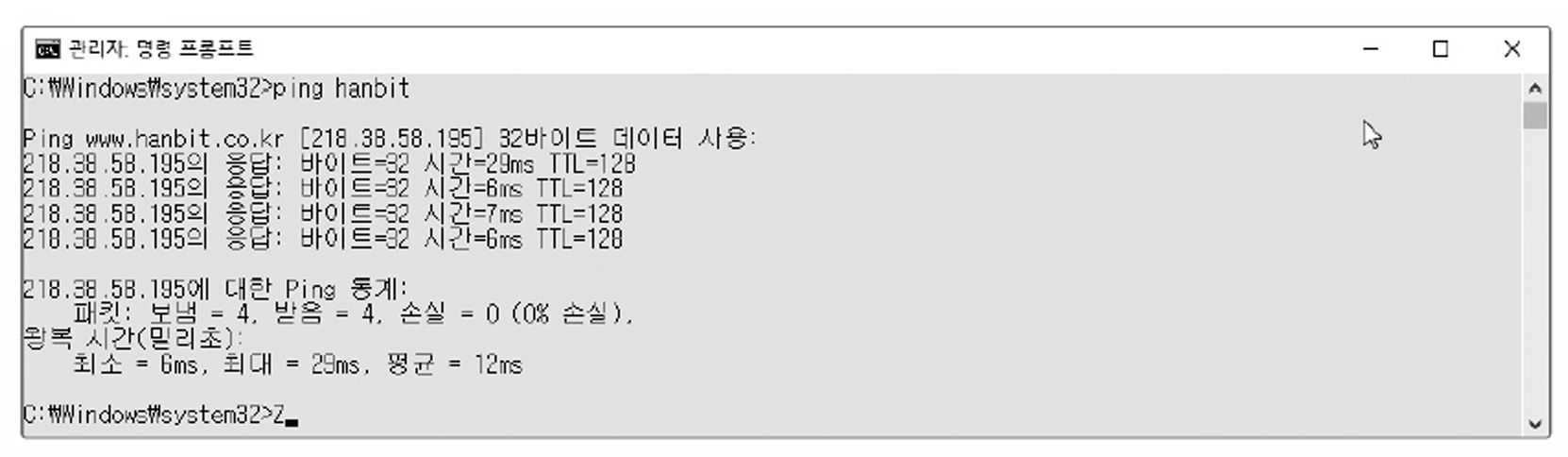
▶ ping hanbit

▶ ping -a www.hanbit.co.kr
3. 잘못된 주소를 등록하여 사이트 접속 차단하기

▶ 200.200.200.200 www.hanbit.co.kr
악용되면 피싱, 즉 가짜 사이트로 유도할 수 있게 된다.
예를 들어, 실제 naver 서버로 가기 위한 올바른 IP 주소는 여러 개가 존재할 수 있다. (CDN, Content Delivery Network를 사용한 분산 처리로 인해) 이때, 해커가 모양만 naver와 같은 가짜 naver 서버의 IP로 바꾸면, 사용자가 naver.com 접속할 때 실제 서버와 가짜 서버를 구분할 방법이 없다. 그래서 결국, 해커의 가짜 사이트에 전부 중계되고, 로그인, 가입 등으로 인 개인 정보는 캐시 당하는 결과가 일어날 수 있다.
이렇듯, DNS는 인터넷 관련 프로토콜 중 피싱, 악성 코드 유포 등에 기여하기에 보안상 중요하다.
DNS의 작동 원리
DNS (Domain Name System)
Domain Name을 IP로 바꾸기 위한 시스템이자 프로토콜이다.
기본적으로 사람이 사용하기 위한 인터페이스는 Domain이라는 이름 체계를 사용하고, 컴퓨터는 오로지 IP 주소, 즉 숫자를 가지고만 라우터를 통해 특정 컴퓨터를 찾아가는 네트워크 통신을 하는데, 이때 DNS는 이 둘을 mapping하기 위한 시스템이다.
DNS의 계층 구조
DNS는 굉장히 분산회된 시스템으로, 체계적이고 계층화된 구조를 가지고 있다.
인터넷 사이트 주소를 보면 . 이 있는데, 이 .은 의미가 크다.
. 을 기준으로, 왼쪽이 더 하위 계층이고, 오른 쪽이 더 상위 계층의 Domain이다.
- 가장 상위 개체는 . (Root)
- 두 번째 개체는 국가와 조직체의 특성
- 보통 맨 앞에 자신의 DNS 서버에서 지정해 놓은 www, ftp와 같은 특정 서버의 이름이 옴
- FQDN(Fully Qualified Domain Name): 완성된 주소 e.g, www.wishfree.co.kr
- Root에 의해 실제론 www.wishfree.co.kr. 이렇게 . 이 더 있다고 볼 수 있다.
www 부분은 여러 가지로 바뀔 수 있고, 이는 서브넷과 관련이 있다. 라우팅, 네트워크의 전체적인 위치에 따라 A, B, C 클래스 대역의 네트워크에서 근거리나 접근성을 기준으로 다른 이름을 사용할 수 있다. 이때, www만 다르고 나머지가 똑같으면 하나의 큰 상위 도메인 아래에 같이 묶여 있는 것이다.
info21.khu.ac.kr or e-campus.khu.ac.kr과 같은 도메인은 공통으로 계층화된 이름 체계를 갖기에 이런 식으로 이름을 짓는다. 이때, 특성 서버에 대해 완전히 일반 닉네임처럼 웹 서버의 도메인을 만들면, 관계가 있는 서버들 사이에 대해 이름을 통해 관계를 유추하기 어렵다. 따라서, 도메인 이름은 관련성 있는 서버들끼리 그룹을형성할 수 있도록 고려해 이름을 지어야 한다.
※ www: 기본적인 웹서버를 의미한다.
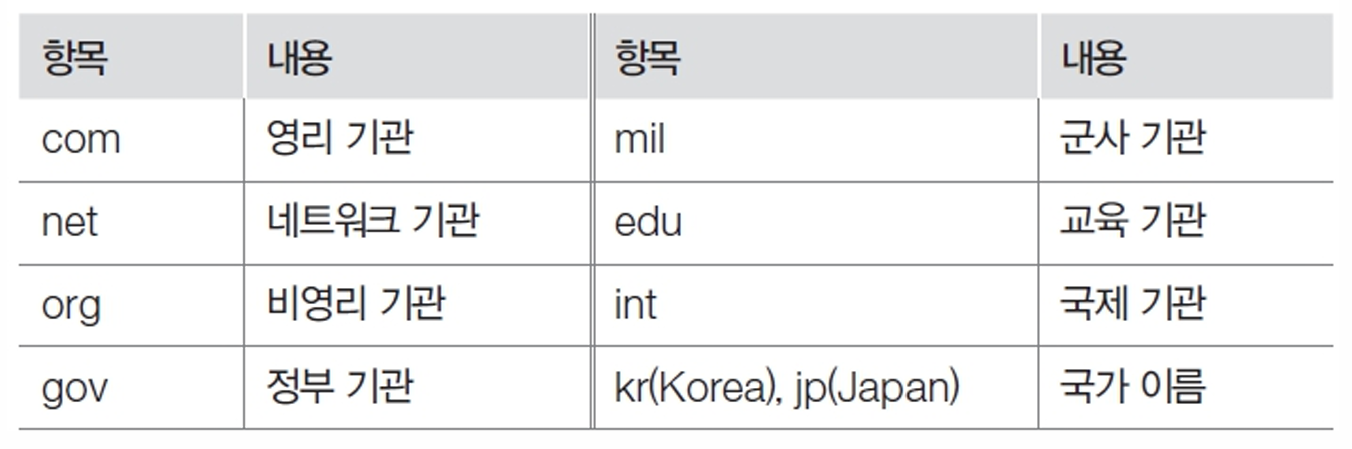
▶ DNS의 두 번째 개체에 대한 내용
이름에 대해 체계화 하여 이름을 부여한다.
때문에, 서버를 만들고 단순히 웹사이트를 돈만 내고 호스팅 받는 게 아니라, 서버의 관리자로서 서버를 구축하려면 공인 IP를 얻고 도메인 이름을 받아야 한다. 공인 IP를 받았다고 해서 그 주소를 직접 사용자에게 제공하는 것은 어렵기 때문에, 도메인 이름을 받아야 하는데, 이때 도메인 이름은 아무렇게나 받는 게 아니라 net, kr 등 도메인 이름을 제공하는 서비스들을 통해 구매해야 한다. 또한, 특정 도메인 이름은 보안 관리가 되어 있는데, 예를 들어 mil 도메인은 군사 관련 용도로만 사용되기에 일반 사용자에게 제공되지 않는다. 이렇듯, 아무렇게나 도메인 이름을 선택할 수 없고, 특정 규칙을 따라야 한다.

▶ DNS의 계층 구조
- 2계층, 3계층은 마음대로 이름을 지을 수 있다.
- 호스트 계층은 관행으로 대략 정해져 있지만, 얼마든지 원하면 이름을 바꿀 수 있다.
운영체제별 DNS 서버 등록
hosts를 사용하고 DNS를 사용하지 않는 것이 아니라, 외부에 전세계적으로 분산화된 DNS 체계(데이터베이스)로부터 IP 주소를 얻어 내겠다 하면, DNS 서버한테 물어봐서 가져오면 된다.
운영체제와 웹브라우저는 서로 긴밀하게 동작하는데, 도메인 이름 해석은 브라우저만 하는 것이 아니라, 어플리케이션 프로그램도 내부적으로 OS와 일을 해 DNS 작동시킨 결과를 가지고 통신을 한다.
윈도우, 리눅스 둘 다 비슷하지만 운영체제 설정으로서 DNS 서버를 지정할 수 있다.

▶ 리눅스의 DNS 서버 설정
- /etc/resolv.cof 파일에 DNS 서버 입력 (e.g., nameserver 127.0.0.53)
- 이때 127.0.0.53과 같은 DNS 서버는 도메인 네임이 아닌 IP 주소로 직접 설정해야 한다.
※ 성능이 아닌 안정성을 원하면 구글과 같은 유명 IT 기업이 제공하는 public한 DNS 서버를 사용해도 된다.

▶ 윈도우의 DNS 서버 설정
- 인터넷 프로토콜(TCP/IP) 등록 정보에서 DNS 서버 두 개까지 입력
- DNS가 인터넷을 하기 위한 중요한 기능이기에, 서버 한 개가 먹통이 되면 다른 백업 서버를 사용하기 위함
- [고급] 버튼을 누르면 좀 더 다양한 설정도 가능

▶ DNS 서버 확인하기 (ipconfig /all 명령)
DNS 서버의 이름 해석 순서

▶ DNS 서버의 이름 해석 순서
- 로컬 DNS 서버: OS에 설정한 DNS 서버이다.
- IP 주소 한 개로 할당되는 DNS 서버 역시 컴퓨터 한 대이기에, 아무리 슈퍼 컴퓨터여도 로컬 DNS 서버 안에서 모든 데이터를 관리할 수는 없다.
- 아주 일부 사본만 가지고 있기에, 반복적인 질의를 하면 과거에 기억했던 정보로 답을 해줄텐데 처음 보는 도메인에 대해 IP 주소가 뭔지 물으면 로컬 DNS 서버가 해결해 줄 수 없다. (이때 cache를 뒤져보긴 함)
- 루트 DNS 서버
- 자신에게도 해당 도메인에 대한 IP 주소가 없으면 하위 계층 도메인에 대한 DNS 서버의 IP 주소를 알려준다.
이렇듯, 전세계의 수많은 DNS 서버가 분산되어 있어, DNS는 대표적인 분산 데이터베이스 형태라고 많이 이야기한다.
※ 위 과정은 cache를 고려하지 않은 경우이다.
캐시된 DNS 정보
매번 DNS 해석 과정을 반복하기엔 부하가 많아, 특정 부분에 cache를 해 놓는다.
로컬 DNS 서버로부터 받은 값을 OS 자체가 cache를 하기도 하고, 로컬 DNS 서버 차원에서도 cache를 하기도 하고, OS와 상관없이 웹브라우저가 스스로 cache를 하기도 힌다. 이렇듯, IP 주소 결과를 어딘가 캐싱해 놓는 어플리케이션이 굉장히 많다.

▶ 윈도우에서 캐시된 DNS 정보 확인

▶ 윈도우에서 캐시된 DNS 정보 삭제
그래서 DNS에 대한 업데이트는 즉각 반영이 잘 되지 않는다. 특정 도메인에 대한 IP 주소가 모종의 이유로 바뀌었을 때, 전세계적으로 바뀐 IP 주소가 적용되고 퍼지려면 통상 몇 분 걸린다.
DNS 레코드의 종류
DNS의 가장 핵심 기능은 도메인 네임을 IP 주소로 바꾸는 것이기에, 보안 관련해선 A, CNAME 레코드만 파악해도 된다.

▶ DNS 레코드 종류
네임 서버는 무엇을 저장할까
DNS resource record
- Record Name (호스트 이름)
- Value
- TTL
- Record type
Record type
레코드 유형이 달라지면 레코드 이름과 값의 의미가 달라진다.

▶ 대표적인 레코드 유형

▶ DNS 레코드 예제
- exaple.com.에 대한 별칭으로 www.example.com. 사용
- www.example.com.에 질의하면 1.2.3.4 응답
- DNS 캐시는 300초간 저장
- 300초 후, 정보가 만료되어 다시 새로운 DNS 요청을 보내야 한다.
IP 주소 추적에 대한 이해
IP 주소 추적의 기본
- 모든 패킷에는 출발지 IP 주소와 목적지 IP 주소가 존재함

과거엔 출발지 IP 주소가 특정 위치를 나타내는 경우가 많았지만, 현재는 IP 주소를 넓은 지역에서 공유해서 쓰는 경우가 많고, 중간에 출발지 IP 주소를 바꿔주는 시스템인 proxy(e.g., VPN)의 개념이 있어 쉽지 않다.
- 중국의 경우, 인터넷 규제가 심하다 보니 인스타그램과 같은 서버에 접속해 해당 서비스를 이용하려면 IP가 차단된다. 때문에 VPN을 통해 IP 주소를 바꿔, 본인의 IP가 마치 다른 나라에 있는 것처럼 속여 시스템 접속을 해야 한다.
VPN과 관련된 게 아니어도 IP 주소가 바뀌는 체계가 있는데, 가장 대표적인 게 NAT이 있다.
이때도 역시 출발지 IP 주소를 확인할 수 없게 된다.
IP 주소 추적을 어렵하게 만드는 NAT (보안)
공인 IP 주소와 사설 IP 주소
- public IP address: 전 세계에서 고유한 IP 주소로, 네트워크 간의 통신, 이를테면 인터넷을 이용할 때 사용하는 IP 주소이다.
- private IP address: 사설 네트워크에서 사용하기 위한 IP 주소로, 사설 IP 주소로 사용하도록 특별히 예약된 IP 주소 공간이다. 때문에 호스트가 속한 사설 네트워크에서만 유효한 주소이기에, 얼마든지 다른 네트워크상의 사설 IP 주소와 중복 가능하다.
일반적으로 네트워크 간의 통신은 공인 IP 주소를 통해 이루어지고, 사설 네트워크 간의 통신은 사설 IP 주소를 통해 이루어진다.
사설 IP 주소를 사용하는 호스트는 외부 네트워크와 어떻게 통신할까?
NAT (Network Address Translation)
IP 주소 변환 기술로, 사설 IP 주소(네트워크 내부)와 공인 IP 주소(네트워크 외부)를 변환한다.
대부분의 라우터와 (가정용) 공유기는 NAT 기능을 내장하고 있다.
- 사설 네트워크의 패킷 속 사설 IP 주소는 공유기를 거쳐 공인 IP 주소로 변경
- 외부 네트워크의 패킷 속 공인 IP 주소는 공유기를 거쳐 사설 IP 주소로 변경
NAT를 통해 사설 IP 주소를 사용하는 여러 호스트는 적은 수의 공인 IP 주소를 공유 가능하다. (N:1)
공유기를 쓰거나, 공공 인터넷을 쓰는 환경에서는 NAT를 통해 내 고유 IP 주소가 아니라 공유기의 IP 주소가 나 대신 사용되는 경우들이 흔하다. 이 경우에는 해킹 공격을 특정 서버로 내가 했어도, 그 서버에서는 내 PC 단말기의 IP 주소를 볼 수 없고 내 IP 주소를 변환해서 보낸 공유기의 IP 주소만 볼 수 있다. 즉, 공유기가 존재하는 위치까지는 파악 가능하지만, 그 공유기를 사용하는 여러 사람 중 누구인지는 알 수 없다.
물론, 공유기를 다시 분해하여 포렌식 분석을 하면 실제 내부망에 IP를 역추적할 수 있지만, 시간과 cost가 아주 많이 소요된다. 때문에 현실적으로 쉽지가 않다. 또한, ISP 업체가 이 망을 어떻게 구성하느냐에 따라서도 IP 주소 추적이 어려워지는 경우들도 있다.
- 대부분의 ISP는 동적 IP 주소를 할당한다. 즉, 고객이 인터넷에 접속하 때마다 서로 다른 IP 주소가 할당되기 때문에, 특정 시점에 어떤 IP가 어떤 사용자에게 할당되었는지를 추적하는 게 어렵다.
※ 단말기: 데이터를 송수신하는 장치이다.
※ 동적 IP 주소와 정적 IP 주소
- 동적 IP 주소: 인터넷에 접속할 때마다 ISP가 자동으로 할당하며, IP 주소 관리를 간편하게 하고, 자원 낭비를 줄이기 위해 사용된다. 주로 가정용 인터넷이나 대다수의 사용자에게 적합하다.
- 정적 IP 주소: 고정된 IP 주소로, 서버나 네트워크 장비에서 사용되며, 항상 동일한 IP 주소를 유지해야 할 때 필요하다. 예를 들어, 웹 서버, 이메일 서버 등의 고정된 주소가 필요한 경우에 사용된다.
서버 로그를 통한 IP 추적
웹 해킹 공격
- 게임이나 포털 업체를 통해 개인 정보가 유출되는 사고의 상당수가 해당
- 해커는 웹 사이트의 구조를 파악하고 공격하기 위해 웹 게시판에 접근
- 서비스의 로그를 분석하면 해커의 IP를 확인 가능
※ 방화벽: 네트워크 트래픽을 모니터링하여 허용된 통신만 통과시켜 불법적인 접근이나 보안 위협을 차단하며, 서버 로그를 분석하여 의심스러운 활동을 감지하고 대응한다.
traceroute를 통한 IP 추적
- traceroute는 패킷이 목적지까지 도달하는 동안 거쳐 가는 라우터의 IP를 확인하는 툴
- 운영체제에서 기본으로 제공하므로 별도로 설치할 필요는 없음
- UDP와 ICMP, IP의 TTL 값을 이용
서버 로그를 통해 소스 IP 주소를 가지고 누가 해커였는지를 찾는 개념이 아니라,
소스 IP 주소를 가지고 특정 서버가 있을 때, 그 서버를 무슨 경로를 거쳐 갔는지 추적하는 개념이다.
- 원리: ICMP 프로토콜의 TTL 값을 일부러 굉장히 낮게 하여 중간 라우터들이 응답하게 만든다.
a.a.a.a에서 b.b.b.b까지 traceroute를 한다고 가정한 동작 순서

▶ 첫 번째 패킷 흐름
- TTL 1 -> 첫 번째 라우터에서 TTL 0이 되어 ICMP 응답

▶ 두 번째 패킷 흐름
- TTL 2 -> 두 번째 라우터에서 TTL 0이 되어 ICMP 응답

▶ 목적지 도달 시 패킷 흐름
- TTL 3 -> 세 번째 라우터에서 TTL 0이 되어 ICMP 응답
- TTL 4 -> 목적지 도착
IP 계층의 라우팅 노드를 하나씩 지날 때마다 IP 패킷에서는 TTL 값을 1씩 decrement 시키는데,
이때 TTL이 0이 되면 소스 IP 쪽으로 문제가 생겼다는 오류 메시지를 준다.
때문에, 일부러 TTL을 1부터 늘려가며 패킷을 보내 단계를 지날 때마다 중간 노드에서 에러 메시지를 받고, 이렇게 에러 메시지를 받을 때 위치 정보가 들어가기에, 이를 통해 a.a.a.a 컴퓨터가 b.b.b.b 서버까지 무슨 경로를 거쳐 갔는지 알 수 있는 것이다.
물론, 이건 절대적인 게 아니고 라우터마다 설정은 바꿔줄 수 있기에, 에러 응답을 안 하는 라우터가 있으면 알 수 없긴 하다.
다크웹과 IP 추적
다크웹
다크웹: 절대 들어가면 안 되는 곳
Web
- Surface Web: 전체 인터넷의 4%
- Deep Web: 전체 인터넷의 96%, 로그인을 해야 들어갈 수 있는 mail, 카톡 등과 같은 사이트
- Dark Web: 전체 인터넷의 5%, 범죄와 이상한 것들이 모이는 인터넷의 심해
다크웹에 접속하기 위해서는 특정한 웹 브라우저인 토르라는 프로그램을 사용해야 한다. 토르는 전 세계에 분산된 서버를 거쳐 인터넷 접속이 이뤄지고 별도 네트워크를 통해 웹페이지에 방문을 하더라도 익명성이 보장된다.
일반 인터넷은 네트워크를 통해 주소를 가지고 찾아가는 프로토콜 개념인데, 다크웹은 이러한 인터넷 망하고는 기본적으로 완전히 다른 체계로 분리가 되어 있다. 특정한 웹 브라우저와 특정한 프로토콜을 통해서만 다크웹 안에서 웹서핑을 할 수 있으며, 이것이 토르 브라우저이다. 그리고 프로토콜은 토르 브라우저가 사용하는 네트워크 프로토콜인 Onion 프로토콜을 사용한다.
이때 Onion 프로토콜이라는 것에 의해서 익명성이 보장되게 된다. 즉, 누가 어떤 IP 주소에서 이런 접속을 한 것이며, 이 서버의 IP 주소 위치는 어디에 있는지 등을 전혀 모르게, 서로 익명성을 보장해서 통신을 할 수 있는 그런 네트워크이다. 그러다 보니 범죄 시장에서 주로 활용된다. 원래 취지는 익명성을 가지고 좋은 목적으로 목소릴 내자는 취지로 만들었지만, 만들고 보니 대부분 나쁜 쪽으로 쓰이는 결과가 나왔다.
이러한 다크웹은 서버를 찾을 수 없는 Hidden Server로, 완벽한 익명성이 보장되는 인터넷이기에, 수사 기관이 어떻게 서버를 찾아낼 거며, 누가 그 서버에 접속했는지 어떻게 추적할 거냐에 대해 관심이 많고, 이는 아주 어려운 기술적 문제이다. 일반적인 인터넷의 사이트들과는 달리, 다크웹 안에 있는 서비스들, 이 웹사이트의 서버에 대한 IP 주소가 노출되는 것은 다크웹 서버에게 매우 치명적인 보안 문제이다.
Onion URL
다크웹 브라우저는 일반 브라우저와 크게 다를 건 없어 보이는데, 한 가지 특별한 것이, 도메인 네임 시스템이다. 다크웹은 DNS를 사용하지 않는다. 일반 사이트에선 도메인 이름에 대한 IP 주소를 아는 것이 어떤 취약점이나 보안 문제가 아니라 당연한 기능이지지만, 다크웹은 다르다.

▶ 다크웹의 도메인 주소 예시
- Onion URL: 다크웹 hidden 서버의 public key에 기반한 hash 값 (Base32 인코딩)
- 마지막이 .onion 으로 끝남 (DNS로 해석할 수 없는 도메인 이름)
이러한 Onion URL은 별도로 처리하는 시스템이 존재하고, 이는 굉장히 복잡하다. 때문에, Onion 형태의 URL은 다크웹 접속이 가능한 웹 브라우저인 토르 브라우저만 해석해 거기에 접속할 수 있고, 일반 웹 브라우저에서 접속하려하면 접근할 수 없게 되어있다.
※ 양파 그림이 토르 브라우저에 들어가 있는 이유: 양파는 껍질을 까도까도 나오고, 다크웹의 익명성과 추적을 숨기는 기본적인 원리가 암호화를 겹겹이 하는 것이기에, 이러한 구조를 Onion 프로토콜이 정의를 함을 비유적으로 표현한 것이다.
Onion 라우팅

▶ Onion 라우팅
- Entry Node: 사용자(Onion proxy)가 유일하게 아는 노드로, Middle Node의 위치만 알고, 사용자의 요청을 첫 번째로 받는다.
- Middle Node: 중간 역할로, 전체 경로는 모르고 앞뒤 노드의 위치만 알고 있다. (Exit Node 위치만 안다.)
- Exit Node: 마지막으로 서버에 요청을 전달해 주는 노드로, 유일하게 Hidden Server의 위치를 알고 있다.
- 때문에 가장 민감하고, Exit Node가 해킹되면, Hidden Server의 위치가 드러날 수도 있기에 보안상 중요하다.
다크웹에서는 일반 인터넷과는 다르게, 인터넷 통신을 Onion 라우팅이라는 것을 통해 하게 되는데, 이는 상당히 복잡하다.
여기서 말하는 Onion proxy는 토르 브라우저를 의미하고, 이 브라우저를 통해 다크웹을 웹서핑한다. 이때 Hidden Server, 즉 다크웹 사이트를 실제 돌리는 서버가 어딘가에 있을 때, 어떻게 둘이 통신하기 위한 암호화된 채널이 형성 되느냐가 중요하다.
이때, 암호화를 해서 통신을 하는 거랑 이 채널이 무슨 노드들을 거쳐 이루어지는 거냐는 별개의 문제이다. 암호화를 했다는 것은 둘 이 주고받는 대화의 내용을 알 수 없다는 거고, 이는 일반 인터넷에서도 HTTPS 쓰면 암호화된 통신을 하니 중간에 도청할 수 없다. 하지만 Onion 라우팅의 핵심은, 통신 당사자끼리도 서로 어디에 있는지조차 모른 채 통신을 한다는 것이다. 그리고 이를 구현하기 위한 네트워크 프로토콜이 Onion 프로토콜이다.
즉, 접속자만 Hidden Server의 위치를 모르는 것이 아니라, Hidden Server의 입장에서도 Onion proxy로부터 무슨 웹 페이지를 달라는 요청이 왔는데, 이게 어디서 누구로부터 온 요청인지 모르고 응답을 해줘야 하는 것이다. 물론, Onion proxy도 Hidden Server에 대해 전혀 모르고 소통을 한다. 그래서 익명성이라는 게 보장되는 것이다.
또한, entry - middle - exit node의 circuit 회선이 픽스되어 있는 게 아니라, 계속 랜덤하게 달라질 수가 있고, 하나의 회선이 갈 때마다 추가적인 암호화 계층이 생긴다. (Layered ENcryption, 양파 껍질) 때문에 IP 추적이 거의 불가능에 가깝다.
Onion Protocol
Onion Protocol의 핵심적인 원리는 비대칭 암호화에 있다. 이러한 비대칭 암호화는 Onion Protocol뿐만 아니라, 굉장히 많은 네트워크 통신의 보안이 의존하는 암호화 알고리즘이다.

▶ 비대칭 암호화 알고리즘을 활용한 Onion Protocol
- 처음에 보내는 토르 브라우저가 4중으로 암호화를 해 놓고, 노드 하나를 지날 때마다 암호화가 하나씩 풀린다.
다크웹 + 암호화폐
정보 보호 관점에서 중요한 것으로, 다크웹과 비트코인(암호화폐)이 합쳐져 엄청난 파급력을 띄며 최근 문제가 되었다. 그래서 랜섬웨어 역시 이 둘과 맞물리며 심각해졌다.
- 비트코인 (익명 거래) -> 다크웹 (익명 정보 거래)
- 다크웹에서 랜섬웨어를 암호화폐로 구입 -> 랜섬웨어: 침투한 컴퓨터에 있는 모든 정보를 암호화해서 인질로 잡고 돈을 요구하는 악성 코드 -> 이렇게 번 돈으로 다시 다크웹에서 새로운 악성 코드 구입 (범죄의 악순환 고리를 만드는 시스템)
웹해킹
웹해킹은 웹 서버나 웹사이트를 공격하는 전반적인 해킹 기법이다.
웹사이트는 크게 두 가지로 구성된다.
- HTTP를 담당하는 웹 서버 e.g., Apache, Nginx
- 웹 어플리케이션 프로그램 로직 담당 e.g, Nodejs, Django, PHP, ASP, JSP, React, Spring boot, Flask
웹 해킹은 대부분 Apache, Nginx 단계에서 하는 해킹이 아니라, Nodejs, Django, 혹은 그 후 Nextjs, React, Spring boot를 대상으로 하는 해킹을 말한다. 물론, Apache, Nginx가 보안 문제가 있어 당하는 경우도 있는데, 이는 기술적으로 난이도가 상당히 높은 편으로, 비율이 그렇게 높지 않다.8
웹 어플리케이션
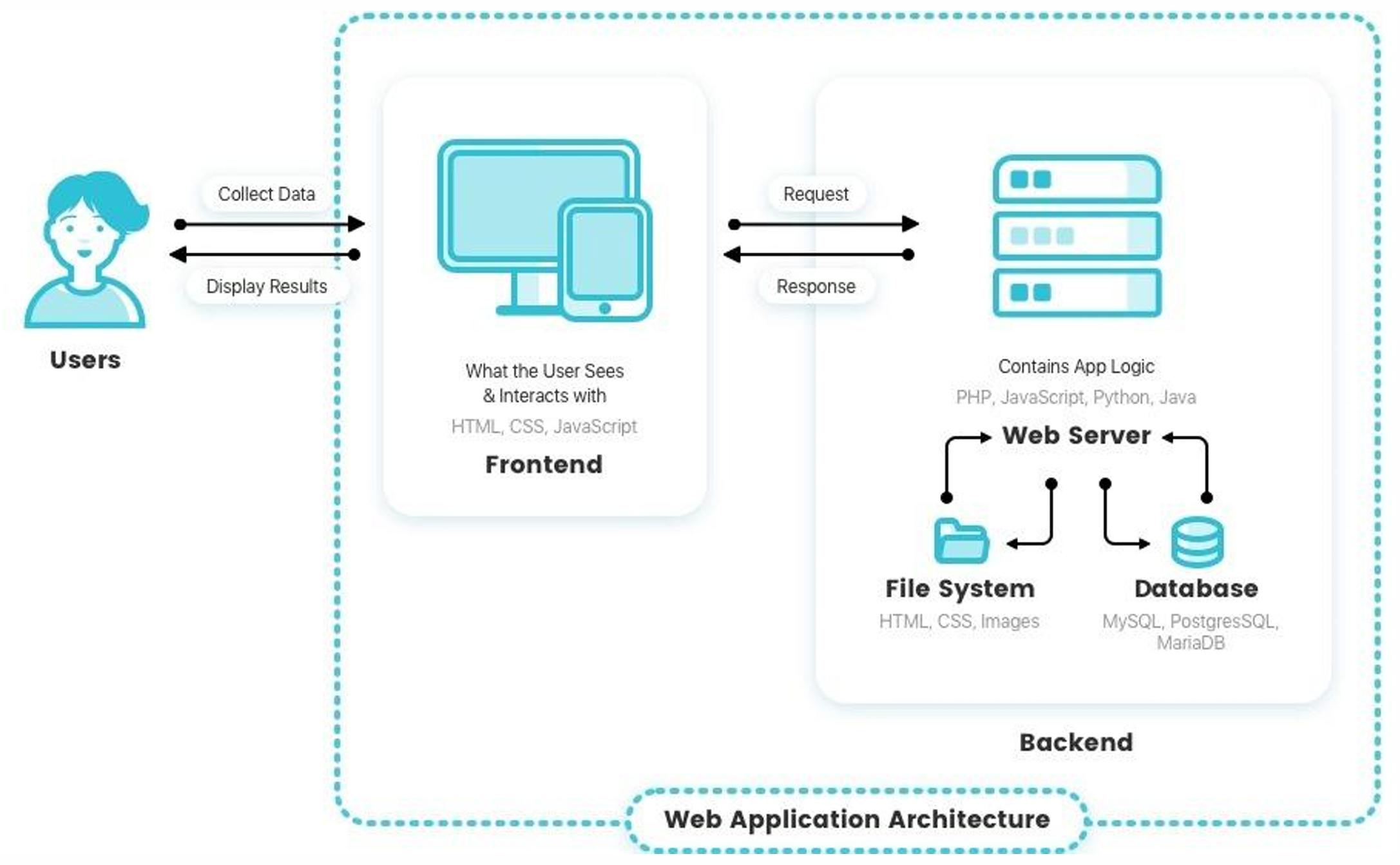
▶ 웹 어플리케이션 구조
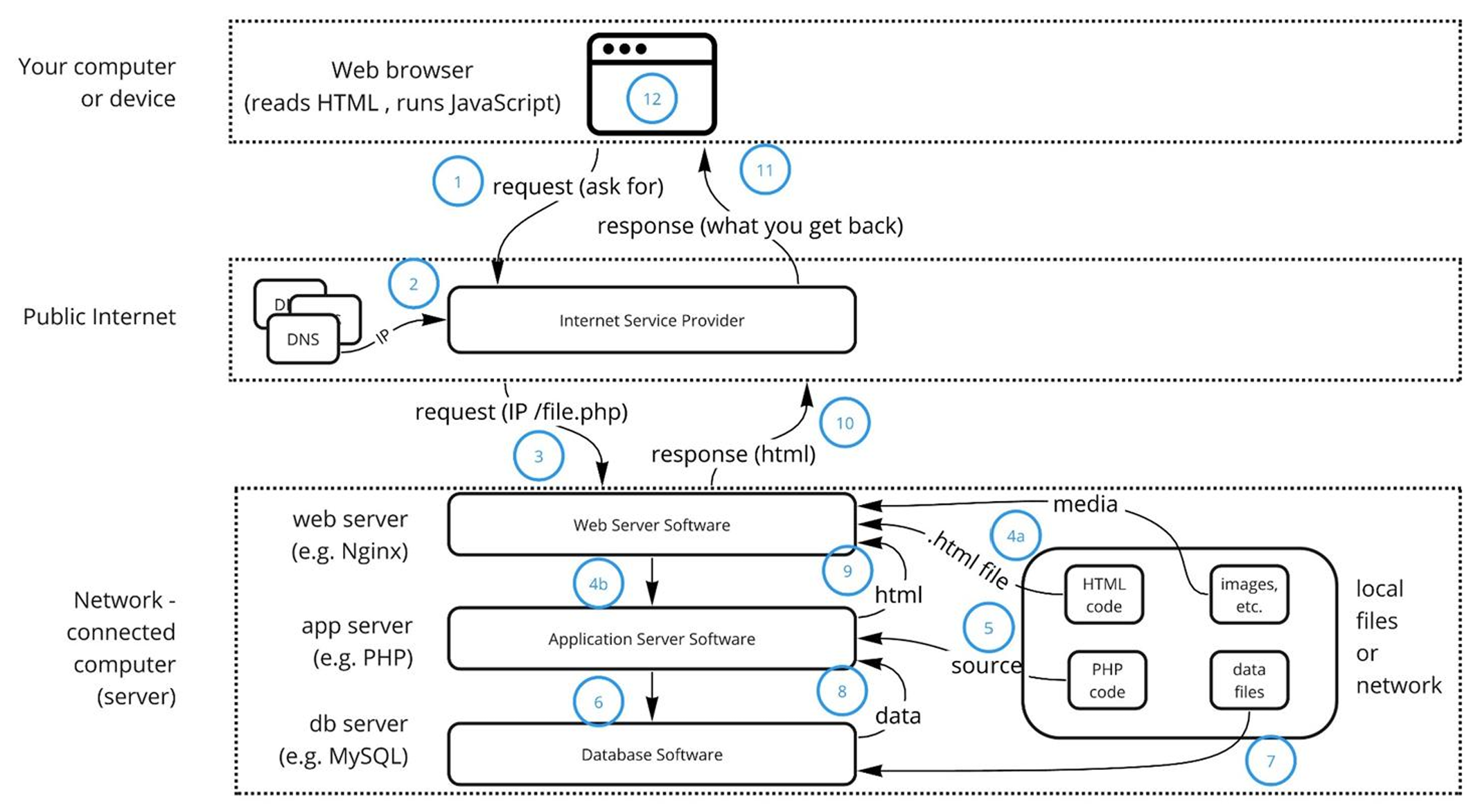
▶ 웹 어플리케이션 구조 (디테일 버전)
Apache, Nginx와 같은 것들은 HTTP Request에 대한 처리만 하고, 웹 사이트의 기능에는 관여하지 않는다.

▶ 웹 어플리케이션 구성요소들
- HTML: 웹 브라우저가 화면에 뭔가를 찍어, 궁극적으로 보여주는 데이터
- JavaScript: 브라우저에서 보는 화면을 동적으로 만들어 주거나, 중간에 동적인 소통을 하는 것을 지원해 주기 위한 웹 브라우저 안에서 실행되는 소프트웨어 프로그램 (코드)
- 해석이 되어 실행이 되고, 이 결과가 브라우저에 반영되는 코드이기에 악성 스크립트가 자바스크립트로 들어오면 안 된다. 때문에 이를 막기 위해, 웹브라우저는 자바스크립트가 지정된 일만 할 수 있게 샌드박싱한다. (기능 제한)
- 웹 관련 보안 문제는 HTML로 인해 발생하는 건 거의 없고, JavaScript에서 대부분 발생한다.
- AJAX: JavaScript의 부분 집합으로, JavaScript가 생성해 보내는 요청 (특정 조건 만족시 사용자 상관없이 스스로 요청 보냄)
- 보안과 관련이 높다.
- JSON: 웹서버가 돌아가는 JavaScript에 대해 응답하는 데이터의 표현 방식 (key-value 딕셔너리 형태 스키마)
- DBMS: 웹 서버 안에서 데이터를 엑세스 해야할 때, 별도의 데이터를 관리하는 웹 서버 내부 망에서의 추가적인 서버
- SQL: 어플리케이션 소프트웨어들이 데이터에 엑세스할 때 DBMS에 요청을 보내 가져와 사용하는데, 이때 사용하는 문법 체계
- SQL Injection이 있어, 보안과 아주 밀접한 연관이 있다. (DB 유출)
- Docker: 통상 서버들은 하나가 딱 있는 게 아니라, 많은 서버들이 상호작용하는 방식으로 웹 어플리케이션이 돌아가는데, 이러한 서버나 어플리케이션을 효율적으로 관리하기 위한 컨테이너 (웹 어플리케이션 deploy, 배포 돕는 플랫폼)
HTTP Protocol
HTTP
HTTP는 웹 브라우저와 웹 서버가 통신하기 위해 설계된 HTML 등의 하이퍼미디어 문서를 통신하는 어플리케이션 계층의 프로토콜이다. 즉, 클라이언트와 서버가 통신할 때 쓰는 약속이다.
특징
- TCP 프로토콜을 기반으로 만들어졌기 때문에 전달받은 데이터는 왜곡이 될 수 없음
- 클라이언트가 '요청'을 하고 서버가 '응답'을 내놓는 1:1 대응 통신
- stateless인 프로토콜이기에, 서버는 클라이언트의 상태를 기억하지 않음 (무슨 요청했는지 기억 X)
- 모든 요청은 독립적임
curl
HTTP를 테스트해 볼 수 있는 도구 (커맨드라인)
$ curl [옵션] <접속할 URL>
HTTP 메시지 형식 - 요청

▶ HTTP 요청
- 시작 줄: HTTP 메서드 + 요청 타겟 + HTTP 버전

▶ 헤더 - HTTP 메서드
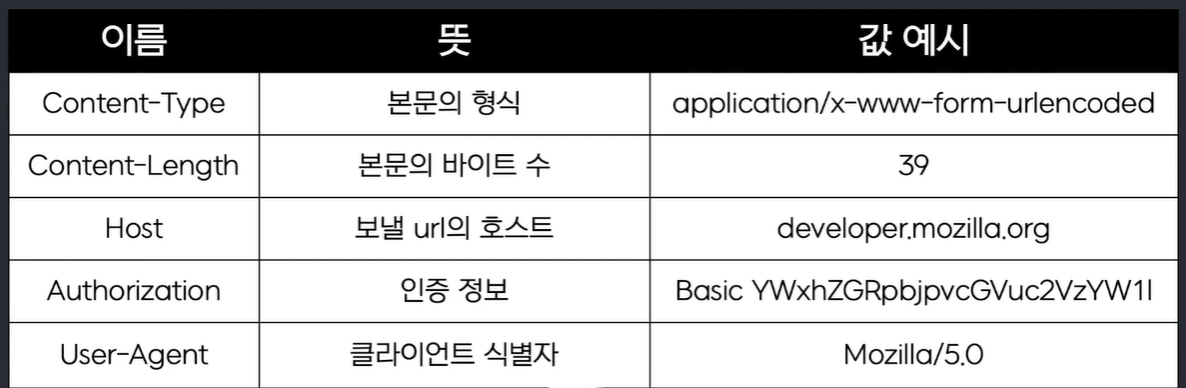

▶ 헤더
HTTP 메시지 형식 - 응
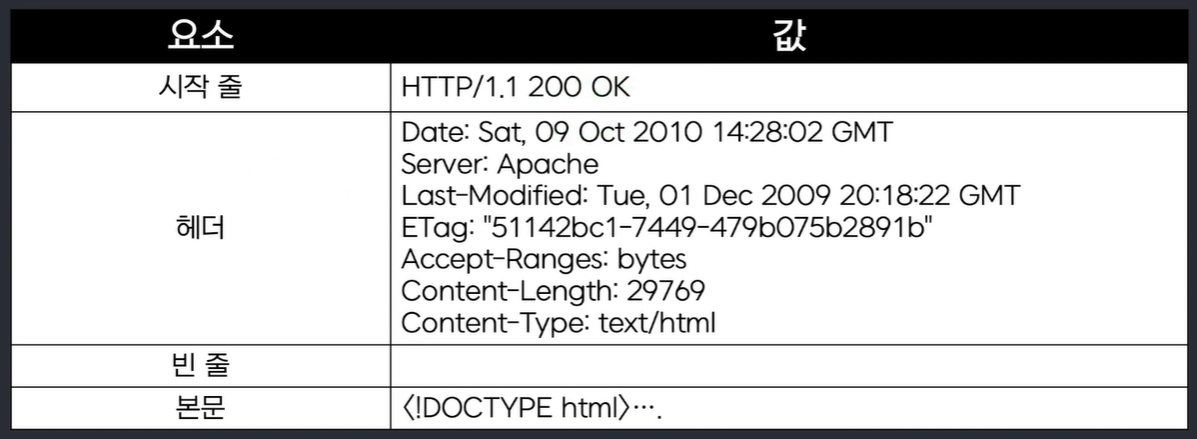
▶ HTTP 응답
- 시작 줄: HTTP 버전 + 상태 코드 + 상태 메시지

▶ 시작 줄 - 상태 코드
※ 하이퍼미디어: 텍스트뿐 아니라 이미지, 영상, 소리 등 다양한 형태의 콘텐츠를 서로 연결해서 보여주는 방식이다.

▶ HTTP Protocol
- 텍스트로 다루기 쉬운 구조로 되어 있다.
TCP 세션이 만들어지면, 즉 연결 설정이되면 데이터 송수신이 가능한데,
이때 보내는 데이터의 모양의 구조가 HTTP Protocol이다.

▶ GET / POST
- 클라이언트(웹브라우저)가 서버(웹서버)에게 보내는 프로토콜 (요청)데이터 요구
- GET: 데이터 요구
- POST: 데이터 전달 e.g., 로그인 시 id, pw 전달
Header
HTTP 프로토콜에서 두 번째 줄부터가 헤더이며, 헤더에서 연달아 엔터가 두 번 오면, 거기서 헤더가 끝난다.
이때 헤더가 존재하는 이유는, 웹 브라우저와 웹 서버가 서로 통신을 할 때 그냥 특정 리소스만 달라는 식으로 끝나는 게 아니라 부가적인 정보가 많이 필요할 수 있는데, 이때 이러한 부가적인 정보들을 헤더를 통해 주고 받는다.

▶ Host
- 서버의 도메인 이름으로, 서버를 식별 (가상 호스팅)
- naver의 리소스 중 뭔가를 달라는 요청을 할 때 붙이는 Host 헤더는 naver.com 이다.
- 하나의 포트 번호, 즉 물리적인 하나의 서버로 와도, 하나의 서버가 여러 개의 웹사이트를 호스팅할 수 있기 때문에, Host 헤더를 통해 식별해야 한다.

▶ User Agent
- 웹 브라우저의 종류를 식별 -> 응답 시 참고

▶ Referrer
- 상위 링크 추적을 위한 HTTP 헤더

▶ Cookie (보안상 중요 e.g., 로그인 정보)
- 웹 브라우저를 식별 e.g., 로그인한 상태인지 아닌지 식별 (세션 ID)
- User Agent는 똑같은 웹 브라우저를 사용하는 사람들은 모두 같은 값을 갖기에 고유 사용자 식별이 안 된다.
- 웹 브라우저와 웹 서버 모두에 저장이 되는 헤더
- 로그인이 되면, 서버는 쿠키를 부여하여 브라우저에 전달한다.
- 웹 브라우저를 사용하는 사람이 로그인한 이후 다시 접속하면, 세션 ID가 헤더에 붙어서 간다.
- 만약, 로그인을 하지 않고 특정 페이지를 보여달라 하면, 쿠키 값이 없는 상태로 GET 요청이 간다.
- 이때, 세션 ID 값을 훔쳐 내 헤더에 붙이면, 로그인 하지 않고도 로그인 한 사람만 볼 수 있는 정보를 볼 수 있다.
※ 대표적인 로그인 방식을 구현하는 방법론으로, 쿠키가 쓰인다. 물론 최근엔, JWT(JSON Web Token)라는 로그인 상태나 권한을 담은 디지털 신분증을 사용하는 방법으로도 많이 구현한다.
웹 해킹을 위해 필요한 기본 개념
웹방화벽
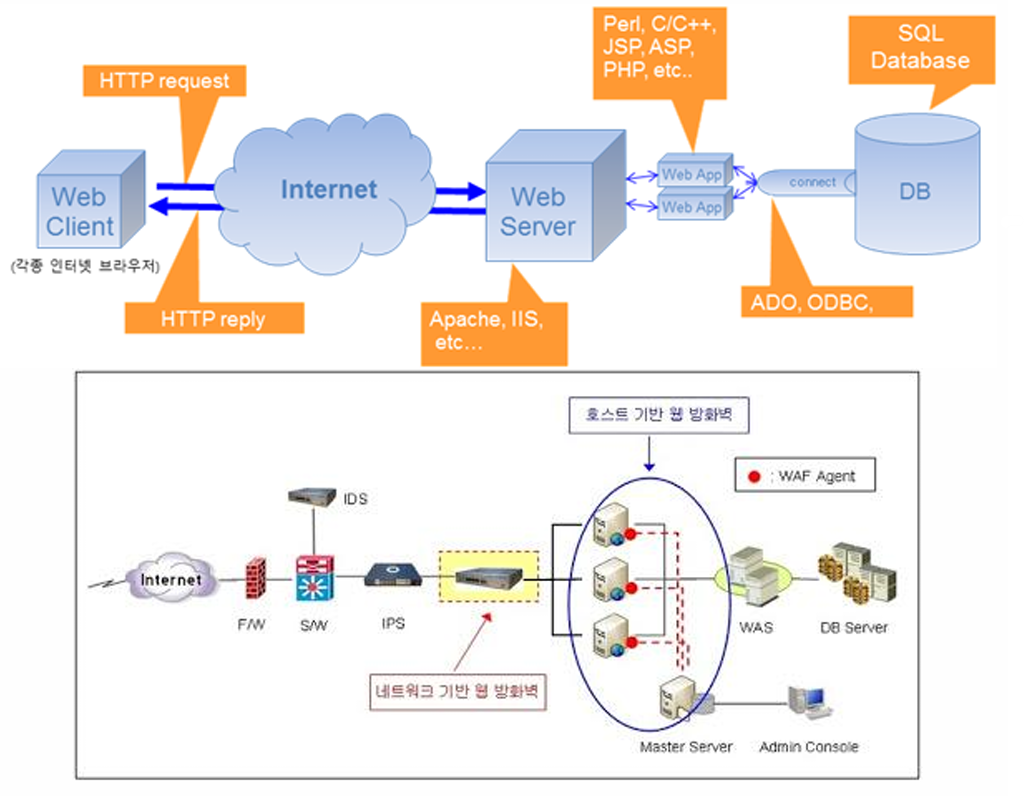
▶ 웹 방화벽
- 웹 해킹에 집중된 방화벽
- 네트워크 통신 트래픽을 보며 여러 룰을 가지고 검사를 하다가, 웹 해킹이 의심되는 패턴이 보이면 drop
- 방화벽으로 원천 차단은 못하고, 공격을 어렵게 만든다. (우회 가능성이 많기 때문)
방화벽이란 네트워크 트래픽에 대해 특정 조건이 만족되면, 그것을차단하는 장치이다.
이러한 방화벽이 들어가는 계층은 다양하다. e.g, OS 레벨의 방화벽, 네트워크 레벨의 방화벽
일반적인 방화벽들은 주로 TCP, UDP 관련해서 특정 포트 번호에 대한 접근 차단, 혹은 특정 IP 주소에 대한 접근 차단을 많이 한다.
- ex) TCP로 네트워크 커넥션을 데스크탑 PC를 가지고 하면, 데스크탑은 대부분 클라이언트로 사용하는 게 전제되어 있는데 왜 굳이 서버의 역할을 하냐며, OS들이 막는다. (방화벽 설정)
Burp - 웹해킹 기본도구

▶ Burp Suite
- 웹에 대한 보안 분석, 디버깅 기능 진단, 취약점 분석, 침투 시도 시 유용한 도구
- 프록시 도구로 layer 7 패킷 데이터 들여다 보기 가능 -> 패킷 수정, 드랍 등 가능
URL 보는법

▶ URL 보는 법
URL에 대한 기본적인 이해가 웹 보안에서 굉장히 중요하다.
HTTPS: HTTP의 암호화된 버전 (보안상 중요)
- GET request와 같은 것들의 모양이 암호화 되어 싹 바뀌는 게 아니라, HTTP가 그대로 있고, 그 위에 한 번 더 암호화가 덮어 쓰여지는 개념이다.
- Burp Suite로 HTTPS도 HTTP처럼 똑같이 패킷 볼 수 있다.
- HTTP: 평문으로 그대로 주고 받음 / HTTPS: 암호화 해서 주고 받음
? (웹 해킹 공격 시 이용)
- PATH와 QUERY STRING을 구분해 주는 핵심 글자
- 물음표 뒤부턴 key-value pair, pair는 &로 구분 -> 여러 변수와 값들을 요청에 실어 보낼 수 있다.
#
- HTML 페이지를 브라우저 입장에서 받았을 때, 어느 위치에 화면을 갖다 놓을 건지 처리 (anchor)
urlencoding

▶ urlencoding
- URL에 자주 사용되는 인코딩 기법: 특수문자 escaping
HTTP 프로토콜은 바이너리 프로토콜이 아니라, 텍스트로 주고 받기에, 문법 구조가 특수 문자에 많이 의존한다.
때문에, ?로 쿼리 스트링을 보낼 때 value 값 자체에 ?가 들어가면, 이를 어떻게 구분할지에 대한 문제가 생긴다.
-> 웹 서버가 해석을 정상적으로 하기 위해 URL 인코딩 필요성
※ 웹 서버에서 urlencoding 문법
- +: 주로 스페이스 바 치환
- 값에 +에 해당하는 게 있으면, 이것도 치환하여 표현 (%도 마찬가지)
- %: 그 다음에 오는 16진수 코드 두 글자를 하나의 바이트로 해석하라는 의미 (유니코드 or 아스키코드로 해석)
아스키코드

▶ 아스키코드
- 컴퓨터가 글자를 메모리에 저장하는 방법
※ 아스키코드: 영어 지원 (ASCII) / 유니코드: 전 세계 언어, 이모지 지원 (UTF-8, UTF-16 등)
Base64

▶ Base64
- 웹에서의 대표적인 인코딩 기법으로, 아스키 코드로 표현이 안 되는 이미지, 파일 등에 대한 인코딩 방법 중 대표적인 것이다.
6비트씩 잘라 매핑 -> 최소 3바이트 = 24비트 필요 (8과 6의 최소 공배수)
- 3바이트 -> 4개의 문자 (4바이트)
- base64로 인코딩하면 정보의 양이 4/3배가 되고, 디코딩하면 3/4으로 비트의 양이 축소된다.
- 부족한 바이트는 0으로 채운다. (padding) -> 패딩 기호 = 로 표현
- ex) 00000000 -base64_인코딩-> AA==
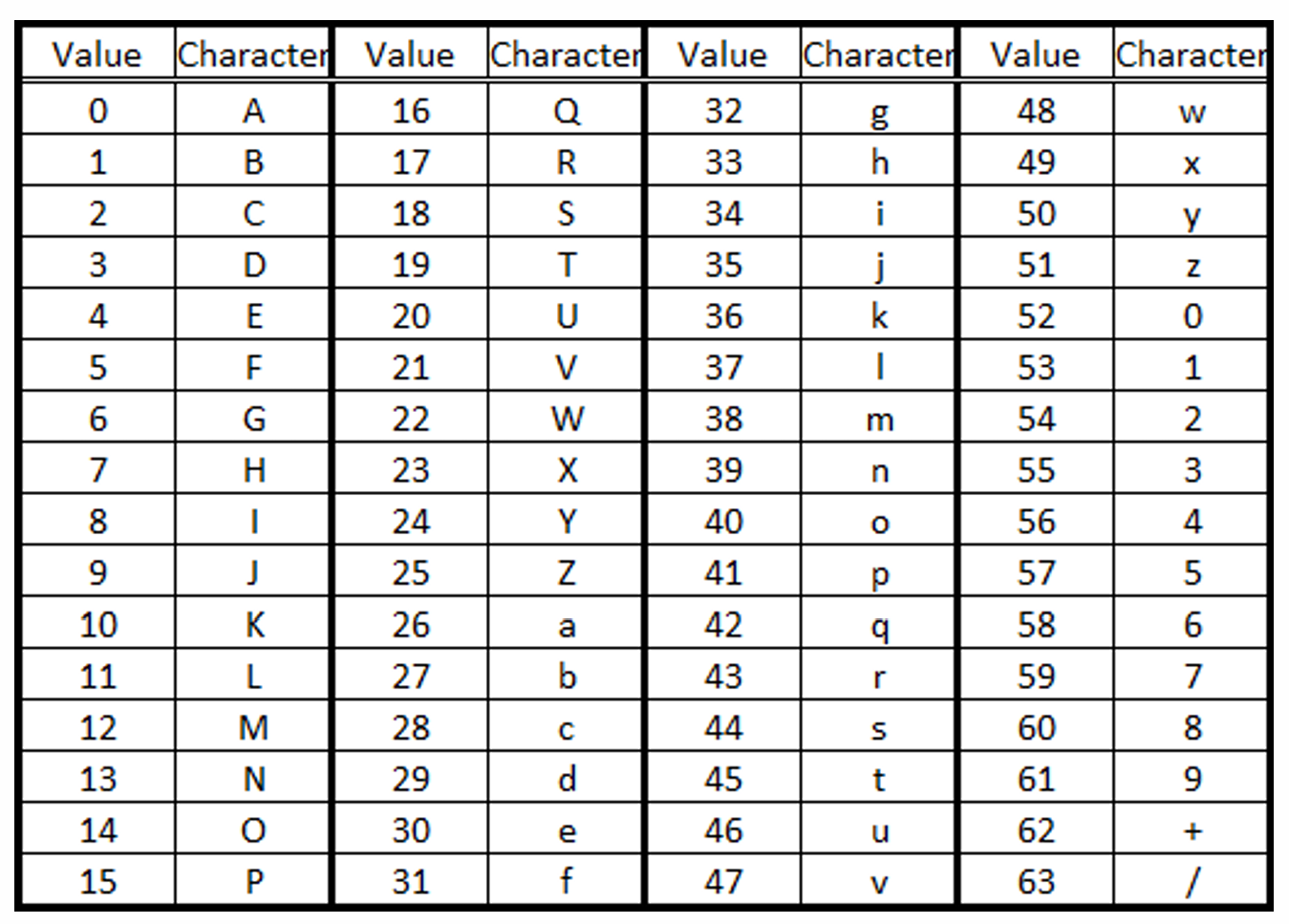
▶ Base64 인코딩 / 디코딩
- 6비트로 표현 가능한 모든 경우의 수에 대해 손쉽게 키보드로 타이핑 및 마우스로 드래그해서 복사, 붙여넣기 가능
- 아스키코드의 경우 키보드로 타이핑이 불가능한 데이터들이 있다.
- ex) 전체가 0으로 구성되는 바이트
즉, 어떠한 바이너리 데이터도 base64로 인코딩을 하면 타이핑 및 마우스로 드래그해서 복사, 붙여넣기 가능한 문자열이 된다.
-> 웹 같은 데서 사용하기 좋다.
웹 어플리케이션의 보안 이슈들
Directory Listing

▶ Directory Listing
요즘의 react, next.js, node.js, spring 같은 거로 개발할 땐 해당 사항이 없지만,
과거에 ASP, PHP, JSP 와 같은 옛날 웹 개발 프레임워크들로 웹사이트나 웹 어플리케이션을 만들면 이 문제가 종종 있었다.
과거의 웹 개발 프레임워크들은 웹 사이트를 그냥 로컬 컴퓨팅 상에서의 폴더 개념으로 생각했다.
그래서 이 취약점이, 취약점이 아니라 의도된 기능이었다.
하지만 개발자들이 실수로 여기에 보안상 민감한 거를 두면, 이게 노출이 되는 문제가 생겨 이젠 문제의 소지가 있는 기능으로 인식한다. 그래서 현재는 디폴트 설정으로 이걸 하지 말자는 웹 어플리케이션의 정책이 바뀌었다.
Local File Inclusion (LFI)

▶ Local File Inclusion
- 웹 어플리케이션 사용자가 비인가된 파일을 접근할 수 있음
- 다운로드 취약점, 또는 파라미터 조작을 통해 다운로드되지 않아야 하는 파일이 다운로드됨
웹 어플리케이션을 개발할 때, 다른 폴더에 있는 파일을 import 하여 활용하는 경우가 많다. 이때, import 할 수 있는 파일의 위치는 특정 폴더 내로 제한되어야 하는데, 이러한 제한이 제대로 설정되지 않으면 문제가 발생할 있다.
예를 들어, 사용자가 ../ 같은 상위 폴더 접근 방식(경로 우회)을 이용해 웹 루트를 벗어난 파일에 접근하게 되면, 서버 내부의 민감한 정보가 노출될 위험이 생긴다.
이처럼 파일 경로 검증이 미흡할 경우, 원하지 않은 파일이 포함되거나 노출되는 보안 취약점이 발생할 수 있다.
$fp = fopen($_GET[$page], "r"); #r: read-only▶ LFI 취약 코드 예시: 웹 어플리케이션 파라미터 조작을 통해 비인가 파일 접근 (PHP 코드 - 옛날 프레임워크)
- ?page=1.txt 같은 파라미터를 통해 /var/www/html/1.txt 이런 경로에 접근하는 걸 의도 했으나, ../ 를 이용하면 /www/html 등을 다 넘어가서 루트로 간 다음 엉뚱한 파일을 가져와서 볼 수 있게 된다.

▶ LFI 취약 결과 예시
업로드 취약점
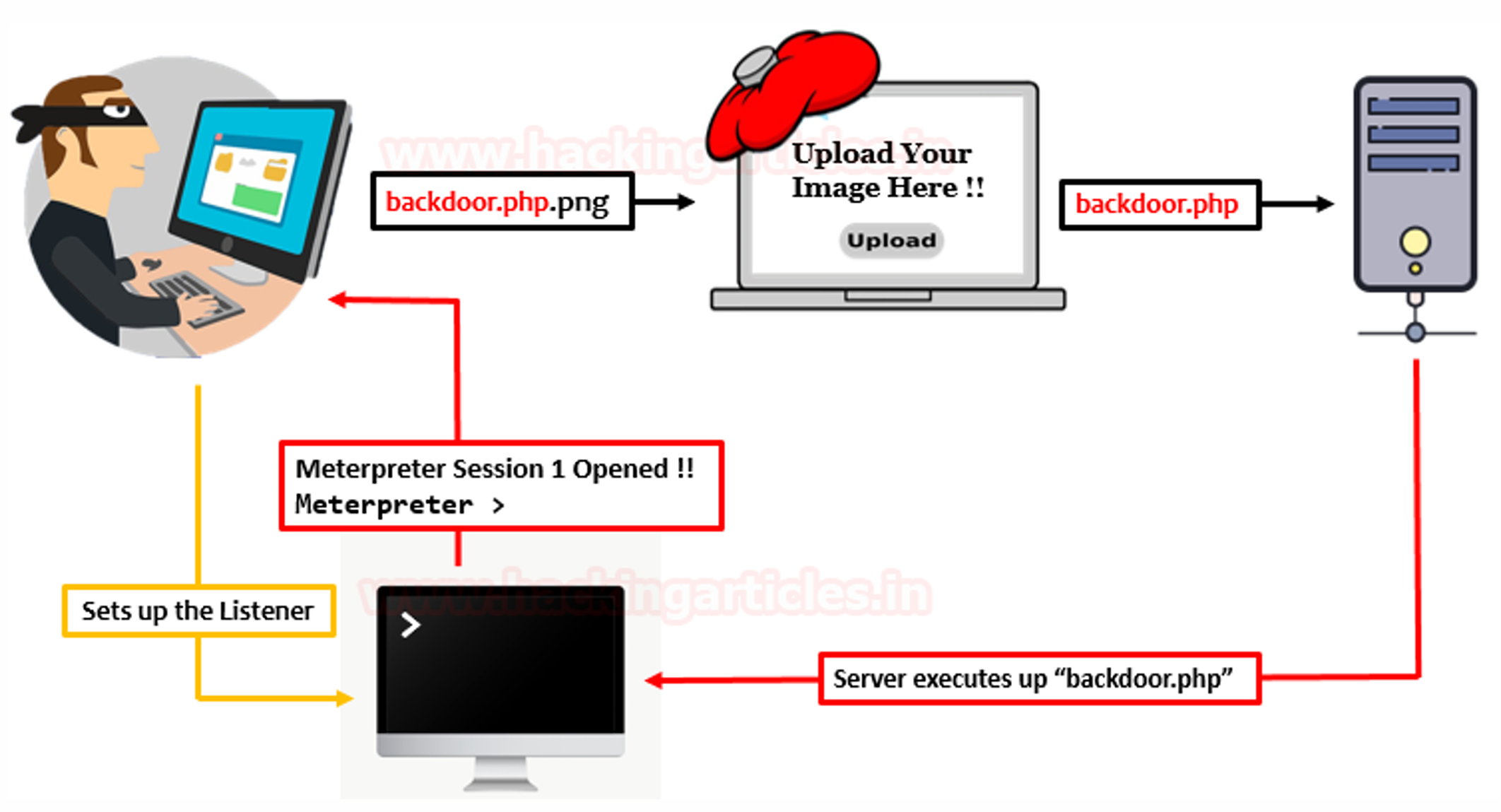
▶ 업로드되지 않아야 하는 파일이 오류로 업로드 됨
- e.g., 웹스크립트를 그림 파일로 가장하여 업로드
파일을 업로드하게 되면, 내가 올린 파일을 다른 누군가가 다운로드하거나 접근할 수 있다. 그런데 웹 서버 입장에서는 루트 디렉터리 아래에 있는 파일들에 대해 확장자나 라우팅 방식(RESTful 구조 등)을 기준으로, 해당 요청이 단순한 리소스 요청인지, 아니면 서버에서 실행해야 하는 스크립트 파일인지를 구분하게 된다.
따라서 파일 업로드 기능을 구현할 때는 확장자 검사, 파일 내용 검사, 파일 저장 경로 및 이름 처리 방식 등 여러 보안 요소를 신중하게 고려해야 한다.
예를 들어, .png 확장자로 위장했지만 실제 내용은 PHP 코드인 파일을 업로드할 수 있다면, 이 파일일 특정 경로에 저장되고 그 경로로 직접 접근이 가능해졌을 때, 서버가 이를 실행해버릴 수 있어 심각한 보안 문제가 발생할 수 있다.
특히, 단순히 업로드된 파일의 확장자로 파일 유형을 판단하거나, 업로드 후 파일 이름을 단순히 바꿔 저장하는 방식은 위험하다.
예를 들어 "backdoor.php.png"라는 파일을 업로드했는데, 이를 서버에서 단순히 확장자 제거 방식으로 "backdoor"라는 이름으로 저장해버린다면, 이 파일이 실제로 PHP 코드라면 서버가 이를 실행할 수도 있기 때문이다.
※ RESTful 구조: 웹 자원을 URL로 표현하고, HTTP 메서드(GET, POST 등)로 그 자원에 대한 동작을 정의하는 방식이다.
※ PHP: 웹 프로그래밍에서의 C 언어와 유사
※ 백도어(Backdoor): 공격자가 은밀하게 서버에 다시 접근할 수 있도록 몰래 설치한 프로그램
웹 쉘

▶ 웹 해킹에 성공한 공격자가 최종적으로 주입
- 웹 사이트에 자신의 제어 프로그램을 업로드
- 주로 PHP로 구성된 백도어 프로그램의 형태
웹 쉘(Web Shell)이란 공격자가 웹사이트에 업로드한 백도어 형태의 스크립트 파일로, 개발자가 의도하지 않은 명령을 임의로 실행할 수 있도록 만든 파일을 말한다. 이러한 웹 쉘을 이용하면 공격자는 서버 내에서 원하는 명령어를 마음대로 실행할 수 있기 때문에, 웹 해킹의 가장 궁극적이고 파급력이 큰 수단으로 여겨진다.
물론, 웹 쉘까진 못 올려도 LFI 취약점을 이용해 서버 내 민감한 파일을 읽거나, 데이터베이스 정보 유출 시키는 것은 할 수 있다.
SQL Injection

▶ SQL Injection
- 데이터베이스 쿼리 언어의 오류로 인한 정보 탈취
- 전통적이고 오래된 웹 보안 이슈
SQL: 웹 어플리케이션과 데이터베이스 서버가 서로 소통하기 위한 언어이다.

▶ SQL Injection의 종류
Blind SQL Injection
- Boolean Based SQL Injection: True/False 기반
- Time Based SQL INjection: Timming 기반

▶ DBMS의 SQL 쿼리문을 웹 어플리케이션 사용자가 조작
- 로그인 우회, 데이터베이스 유출 가능
1=1 attack: SQL 조건문에 항상 True가 되는 구문을 삽입해 인증 우회나 데이터 조회를 유도하는 기본적인 SQL 인젝션 기법이다.

▶ 로그인 우회 코드 예시 (ASP)
단순한 문자열 결합만으로 구문을 생성하면서, 특수 문자 escap을 안 했을 때 injection이 발생한다.
때문에, SQL 구조를 깨뜨리는 특수 문자를 다 필터링, 즉 escape 처리를 하거나 SQL statement 자체를 자체를 생성하는 별개의 API나 기능을 사용해 방어할 수 있다.
요즘엔 이게 알아서 잘 처리가 되지만, 과거에는 신경을 안 쓰면 문제 소지가 있었다.

▶ DB 개인정보 유출
- Union을 통한 추가 SELECT
Prepared Statement
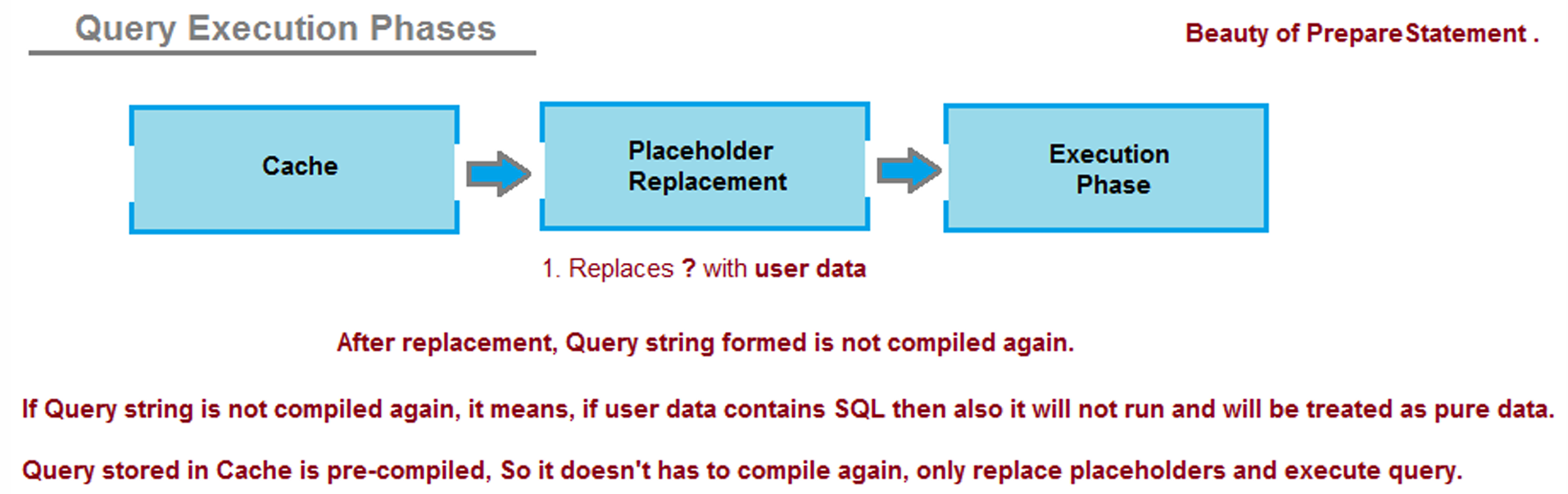
▶ SQL 인젝션의 효과적인 방어
- Dynamic SQL Query Generation
최근 개발 언어들은 SQL 구문을 일반 문자열이 아닌 별개의 함수를 가지고 자체적으로 문제가 없도록 처리해 준다.
Blind SQL Injection
스무고개와 같은 개념으로, 데이터를 직접 볼 수는 없고 쿼리의 True/False 여부만 알 수 있다.
Select .... From [테이블] where [조건]
- Where 절의 조건을 True/False로 결정
- True: 레코드를 1개 이상 (전체) 가져 옴
- False: 레코드를 안 가져 옴
다양한 취약점이 있을 수 있지만, 현실적으로 테이블을 바꾸거나 Select, From 이런 키워드 자체를 바꿀 수 있는 경우는 많지 않다.
대부분 조금 필터링을 잘 못 했을 때, 이 조건 부분에 대한 조작이 가능한 경우가 많아, 옛날 PHP로 만들어진 웹들은 대충 만들었으면 거의 절반 정도는 이 취약점이 아마 있었을 것이다.
select * from BOARD where no=1234 or 1=2▶ 쿼리
위와 같이 쿼리를 조작하면 "1234 or 1=2" 가 조건이 되어 1234번의 게시판 글이 있던 없던 상관없이, 뭔가를 하나 그냥 들고 와서 보여줄 것이다. 이때 뭘 들고 오게 되는가는 DB의 구조에 따라 다르다.

▶ Blind SQL Injection Attack
- John or 1 = 1: 모든 레코드를 가져 옴
- John and 1 = 2: 내가 궁금한 조건 확인 가능
또한, 앞에 불가능한 조건(무조건 False -> 아무것도 안 가져 옴)을 달고, 내가 궁금한 조건을 or로 추가로 달면, 내가 궁금한 조건이 True인지 False인지 확인할 수 있다. (조건절 control하여 원하는 정보 추출 가능)
99999 or id=4 and substring(password, 1, 1)==CHR(0x41) --▶ 레코드를 가져오면(TRUE), 4번 id를 갖는 사람의 password 필드의 첫 번째 글자 값이 A임을 알 수 있다.
이런 식으로 query를 계속 보내고 응답을 받고를 반복하며, True로 조건이 evaluation 됐는지, False로 조건이 evaluation 됐는지를 관측하면 결국 모든 데이터베이스 안에 있는 정보를 시간 문제이긴 하지만 다 긁어올 수 있다.
- 이진 탐색을 사용하면 시간 줄일 수 있다. (성능 최적화)
※ 16진수로 41은 A이며, 99999는 불가능한 조건(해당 데이터베이스에 존재하지 X)이라고 가정한다.
select * from bbs where id = (select id from user where name='haha')▶ sub 쿼리
- where 절의 조건속에서 다시 select 가능
이러한 SQL Injection은 DB 구조를 알아내는 걸로 시작하고, DB 구조를 다 알아내면 그걸 가지고 테이블 안에서 레코드를 꺼내오고 이런 식으로 진행이 되는 것이다. DB 구조를 알아야 select의 where 절을 제어할 수 있다.
where no=10 and length((select password from MEMBERS where uid=10)) > 8 --▶ DB 구조 알아내기 위한 질문
- 회원번호 10번의 비밀번호의 길이는 8보다 큰가?
SQL Injecton에서 중요한 함수
- Length 함수: 문자열의 바이트 길이를 가져 옴
- select length('hello') -> 5
- substring 함수: 문자열의 부분 문자열을 가져 옴
- 문법: substring(문자열, 시작 위치, 길이)
- select substring('hello', 2, 1) -> e

▶ Time based SQL Injection
True/False 결과도 알 수 없는 경우, 즉 응답 자체를 안 하는 경우에 시간을 측정하면, 이를 통해 T/F을 유추할 수 있는 경우도 있다.
Cross Site Scripting (XSS)
JavaScript의 보안에 대한 문제로, AJAX, Fetch 기능과 연관이 깊다.
웹 서버 쪽에서 의도하지 않은 JavaScript가 돌아가 발생하는 문제를 말한다.

▶ JavaScript: 웹사이트를 동적으로 만들어주는 요소
※ AJAX, Fetch: 페이지 리로드 없이 백엔드와 통신
XSS 종류
1. Reflected XSS
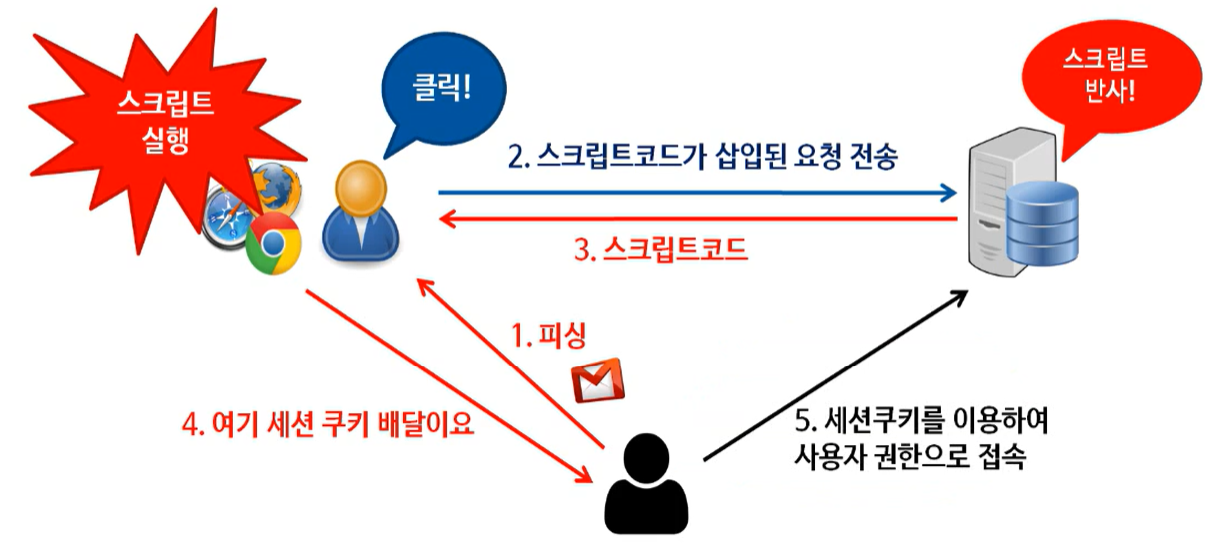
▶ Reflected XSS
2. Stored XSS
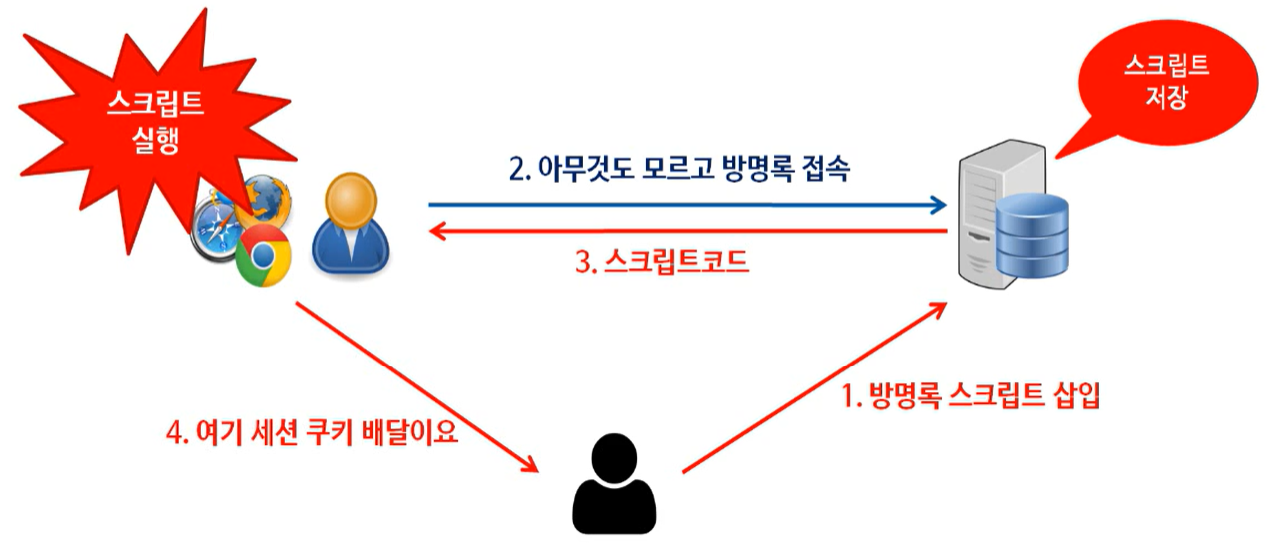
▶ Stored XSS
Reflected XSS

▶ 예시: document.write 속에서 JavaScript가 실행될 여지 존재
웹 어플리케이션의 기능 중 사용자들끼리 상호작용할 수 있는 기능이 있는데,
이를 이용해서 A 사용자가 B 사용자의 웹 브라우저에서 본인이 의도한 자바스크립트를 돌릴 수 있는 것을 말한다.

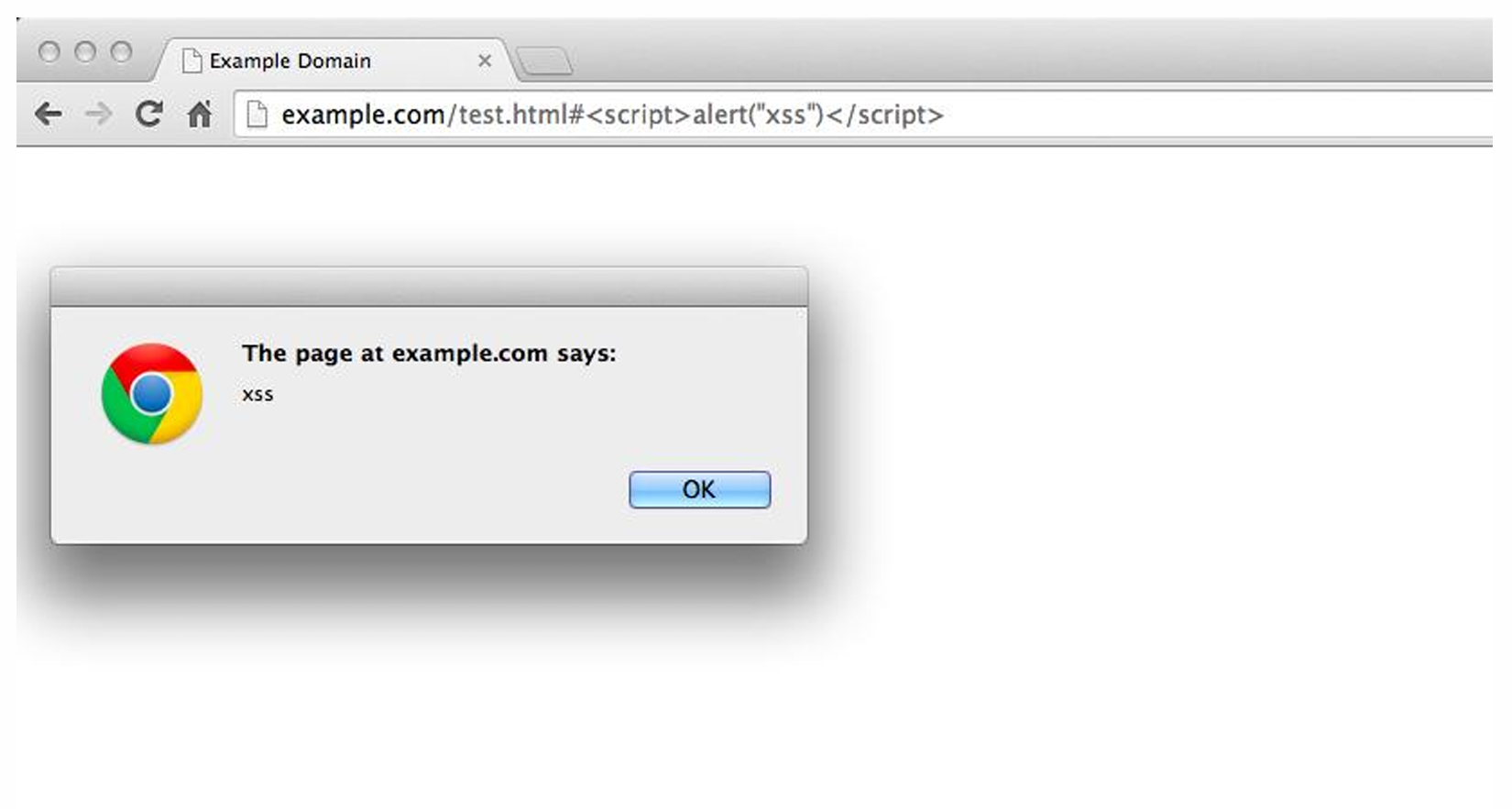
▶ 예시: example.com에서 제공한 JavaScript를 돌리는 상황에서, 그 script가 엉뚱한 사람이 조작한 것으로 돌아가는 상황
XSS가 위험한 이유
1. 쿠키 탈환
- 로그인 세션
- 기타 개인정보
- CSRF Token도 탈취 가능
※ CSRF Token: 사용자의 요청이 위조인지 아닌지 확인하기 위한 보안용 1회용 코드
2. 키로깅
- 마우스/키보드 이벤트 후킹
※ 키로깅: 사용자의 키보드 입력을 몰래 기록하는 기술 / 후킹: OS나 프로그램이 정상적으로 처리할 이벤트(e.g., 키보드 입력, 마우스 클릭 등)를 가로채서 공격자가 원하는 대로 바꾸거나 감시하는 기술
3. 피싱유도
- 가짜 form 및 가짜 화면 제공
CSRF (Cross Site Request Forgery)
CSRF 공격
사이트 간 요청 위조 공격으로, 주로 피싱을 활용해 사용자 모르게 패스워드를 변경하는 것에 사용한다.
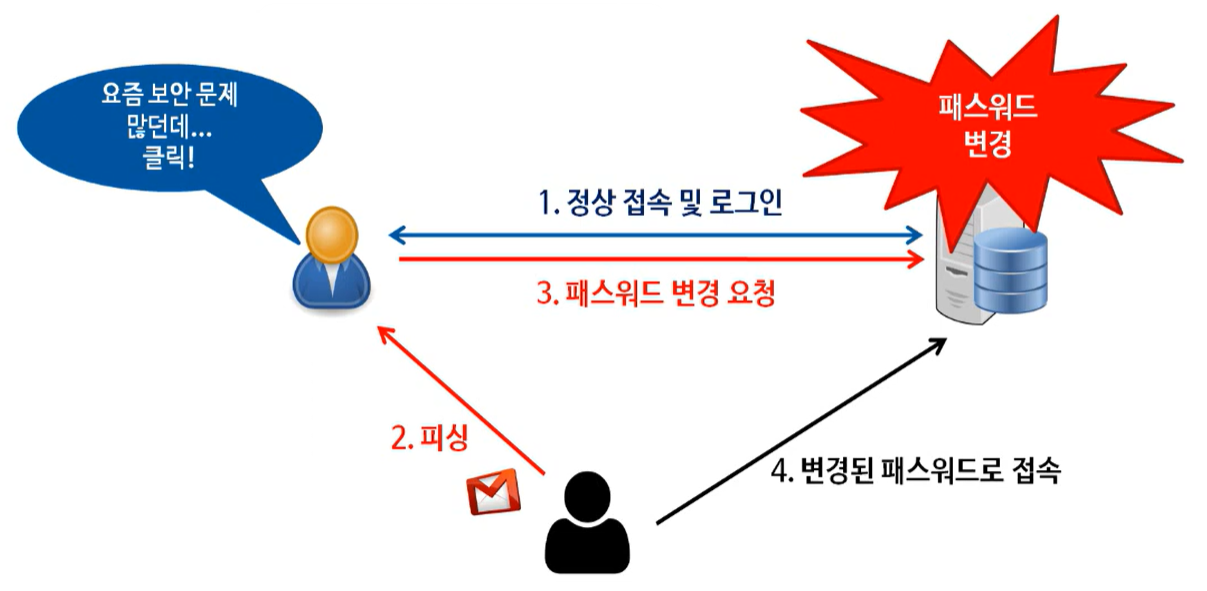
▶ CSRF 공격
- 해커가 지정한 패스워드로 변경
- 필수 조건: 사용자가 피싱을 당해 링크를 누르는 시점에 사이트에 로그인이 되어 있어야 함

▶ CSRF

▶ CSRF Token (방어)
- 서버 측에서 Random 생성한 CSRF Token을 삽입하여 방어
- <input type="hidden" name="csrf-token" value="ClwNZNIR4XbisJF39l8y......"/>
- 정상적인 activity history 추적하여 토큰 생성 -> step을 건너뛰는 요청 무시
※ XSS를 잘 하면 링크를 굳이 누르게 하지 않고도 요청을 보낼 수 있기에 CSRF를 할 필요가 없다.
웹 브라우저 보안계층

▶ 웹 브라우저 보안계층
웹 브라우저 보안이란 웹사이트 이용 중 발생할 수 있는 악성 코드 감염이나 시스템 공격을 방지하는 것으로, 단순히 브라우저 내부 정보 유출을 넘어서 사용자의 PC 전체가 랜섬웨어 등에 감염될 수 있는 위험까지도 포함한다. 참고로, 지금까지 배웠던 XSS, CSRT 같은 공격들은 웹 서버 관련 보안이다.
이러한 공격은 웹 사이트 해킹과 연결될 수도 있지만, 주로 브라우저 자체의 취약점으로 인해 발생하며, 파급력이 크다.
파급성에 대해선 취약점에 대한 버그 방지표를 보면 된다.
※ 이러한 해킹을 할 수 있는 취약점은 취약점 거래 사이트에서 돈을 주고 사고 팔기에 종목별 가격이 나와 있다.
※ 웹사이트 vs 웹 어플리케이션
- 웹사이트: 정보를 보는 곳 e.g., 뉴스, 백과사전
- 웹 어플리케이션: 사용자가 무언가를 하는 곳 e.g., 이메일, 인터넷 쇼핑
참고자료
https://www.youtube.com/watch?v=Ec95htqcMfQ&t=33s
https://www.youtube.com/watch?v=SJgnp7JZ3xE&t=259s
https://www.youtube.com/watch?v=VEsBIWsuwGA
https://www.youtube.com/watch?v=kVKcCFdQAMo
https://www.youtube.com/watch?v=jvS45jdz1ao
https://www.youtube.com/watch?v=atNmPzdvPD4
'CS > 정보보호' 카테고리의 다른 글
| 해킹 문제 풀이 실습 (Crypto) - 1 (0) | 2025.04.17 |
|---|---|
| 2. 보안을 위한 네트워크 이론 (2) | 2025.04.04 |
| 해킹 문제 풀이 실습 (http_hack) - 2 (1) | 2025.04.03 |
| 해킹 문제 풀이 실습 (http_hack) - 1 (0) | 2025.04.02 |
| 1. Introduction (0) | 2025.04.02 |