경희대학교 중앙동아리 쿠러그의 정보보안 강의를 기반으로 정리한 글입니다.
파일
파일이란 데이터를 컴퓨터 저장 장치에 개별적으로 기록하기 위한 컴퓨터 자원이다.
파일 타입
어떤 형식의 데이터를 저장하는지를 표현하는 방식이다.
- Text File, Executable File, Compressed File, Document File, MP3, MP4 등
Computer Storage Device
디지털 데이터를 저장할 수 있는 장치이다.
- 자기테이프, HDD, RAM, SSD(Flash Memory) 등
저장장치 접근
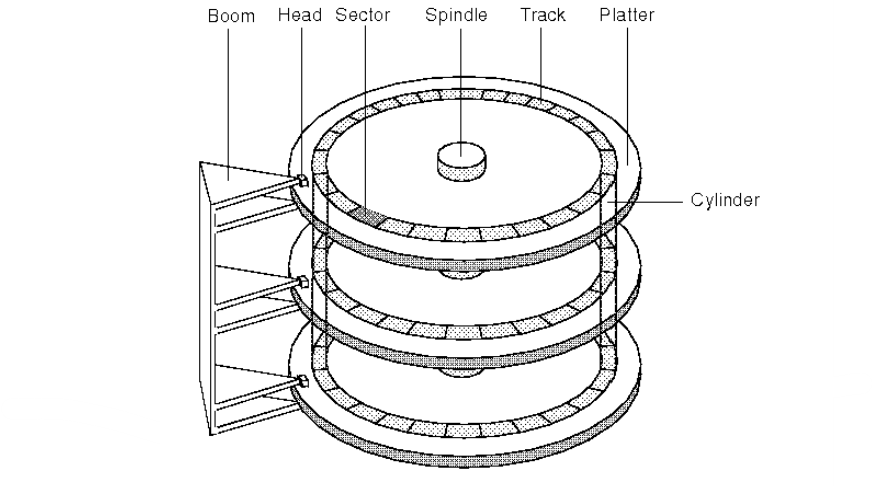
▶ HDD: 자기적인 방식으로 데이터 저장
- 플래터: 수많은 N극과 S극으로 데이터를 저장하는 판 (일반적으로 양면 모두 사용)
- 스핀들: 플래터를 회전시키는 것 (회전의 단위: RPM, Revolution Per Minute)
- 헤드: 플래터를 읽고 쓰는 수단 (일반적으로 모든 헤드가 디스크 암에 부착되어 함께 이동, 디스크 암: 헤드를 움직이는 것)
- 실린더: 여러 겹의 플래터 상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적 단위 (원통 모양)
- 연속된 정보는 한 실린더에 기록, 그 이유는 헤드를 움직이지 않고도 곧바로 읽을 수 있기 때문
- 섹터: 저장 장치의 물리적 단위로, 실제 데이터를 읽고 쓰는 가장 작은 단위 (하드웨어 수준에서 성능과 효율에 영향)
※ HDD 데이터 접근 과정: 탐색 -> 회전 -> 전송, 때문에 HDD 접근이 느림
클러스터
파일 시스템이 데이터를 저장하는 기본 논리 단위로, 파일 저장 시 할당되는 최소 공간 단위이다. (기본적으로 차지하는 공간)
이때, 클러스터는 파일 저장 효율성에 영향을 미치며, 하나의 클러스터(논리)는 여러 섹터(물리)를 의미한다.
LBA (Logical block Address)
간단한 선형 주소 저장 방식으로, 블록이 정수 인덱스로 지정된다.
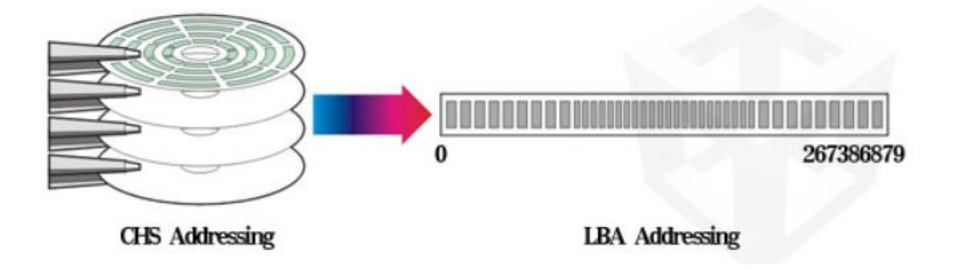
▶ CHS 방식 -> LBA 방식
- CHS 방식: Cylinder Head Sector의 약자로, 실제 물리적인 디스크의 위치를 고려한 물리적 주소 지정 방식으로, Cyliner -> Head -> Sector 순으로 주소를 지정
- (0,0,1), (0,0,2), (0,0,3), ...
- LBA 방식: 디스크를 논리 블록이라는 일정한 크기의 공간들로 이루어진 1차원 배열처럼 취급하며, 논리 블록 하나가 섹터 하나와 1:1로 매핑되어 저장
- 0, 1, 2, ...
실직적으로 데이터에 접근할 때는 클러스터, 섹터 단위가 아닌 LBA 단위로 접근한다.
- LBA 22: 2^22까지 표현 가능 (22bit를 block addressing에 사용) - 1994년 이전 (용량 표현 한계)
- LBA 28: 2^28까지 표현 가능 - 1994
- LBA 48: 2^48까지 표현 가능 - 2003 (한 번에 다룰 수 있는 용량 굉장히 커짐)
-> 숫자가 커지면 그만큼 많은 공간 차지하게 되기에 비효율적, 때문에 작은 숫자를 썼던 것임
파일 시스템
저장장치에서 파일을 관리하기 위한 방법이다.
주요 역할
- 저장 장치에서 파일을 어떻게 읽을 것인가?
- 저장 장치에 파일을 어떻게 쓸 것인가?
- 저장 장치에 파일을 어떻게 변경할 것인가?
저장 장치 접근
- seek: 디스크에서 특정 위치로 이동
- read: 디스크의 현재 위치에서 특정 크기만큼 읽기
- write: 디스크의 현재 위치에서 특정 크기만큼 쓰기
-> 이 세가지 저장 장치 접근이 모두 다 이루어진다는 가정하에 파일 시스템 작성할 수 있음
실습 1
1000 byte 파일 하나만 딱 저장할 수 있고, 읽을 수 있는 아주 간단한 파일 시스템을 만들자
해당 파일 시스템에 파일을 저장하기 위해서는 어떤 정보가 필요할까?
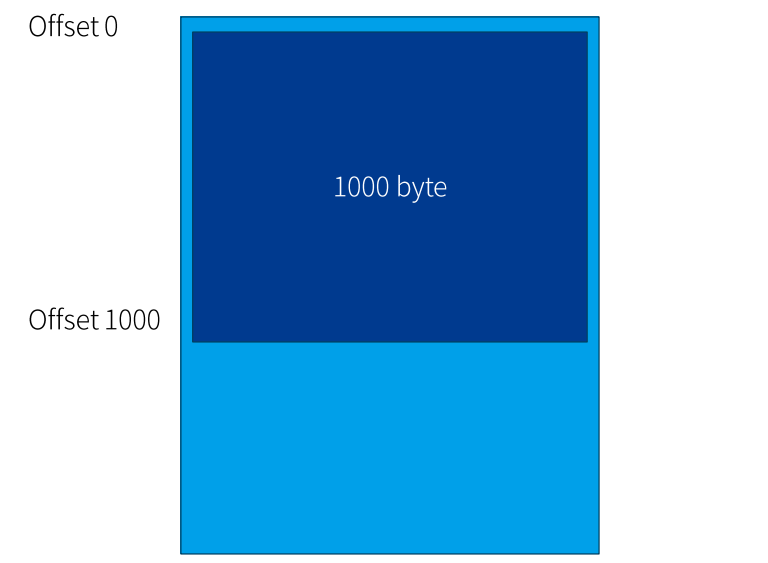
▶ 0부터 저장한다고 파일 시스템을 고정하면 끝임
실습 2
실습 1의 파일 시스템에 크기가 가변인 두 개의 파일을 저장할 수 있어야 한다면, 어떤 정보가 필요할까?
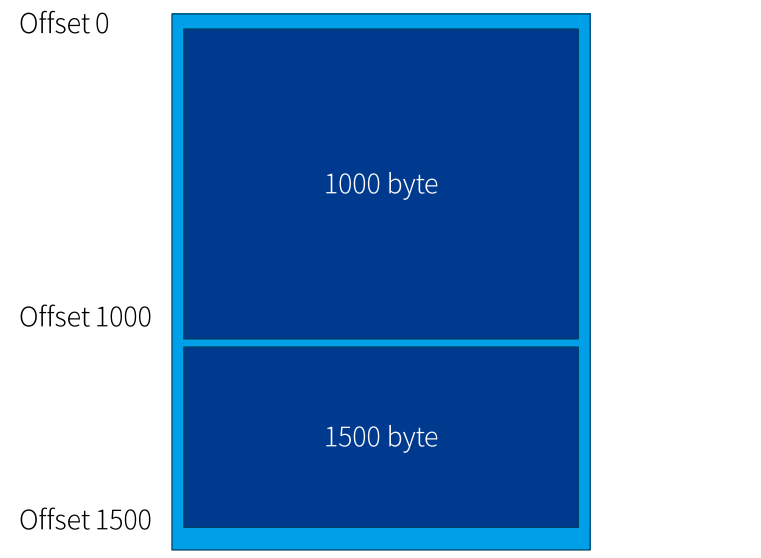
▶ 연속으로 붙여 놓으면 됨
이게 가능할까?
가능하지 않음
- 파일 크기를 모르기 때문에, 두 번째 파일은 찾기 어려움
- 파일이 파손되지 않았음을 보장할 수 없음
Metadata
Metadata란 파일 저장에 필요한 정보를 말한다.
- e.g., 파일의 이름, 크기, 소유권, 생성 시간, 접근 시간, ...
파일 시스템은 기본적으로 어떻게 파일을 찾을지, 그리고 파일이 저장된 게 맞는지, 어떻게 찾을지, 어디서부터 찾을지, 파일 크기는 얼마인지 등 이런 것들을 다 알려줘야 된다. 또한 좀 더 생각해 보면, 파일이 언제 만들어졌는지, 파일의 이름이 뭔지, 파일에 언제 접근했는지도 궁금할 수 있다.
이런 것들을 따지다 보면 굉장히 많은 부가 정보들이 필요하게 되는데, 이러한 부가 정보들을 Metadata라고 하며,
이러한 Metadata는 파일과 같이 저장된다.
실습 1

※ CRC: 오류 검증 코드
고민거리
- 파일 이름에 얼마나 데이터를 할당해야 할까?
- 파일 사이즈에 얼마나 데이터를 할당해야 할까?
- 여러 개의 파일을 저장할 수 있다고 한다면 어떤 정보가 필요할까?
-> Metadata 결정에 따라 파일 시스템의 한계도 결정
이렇게 Metadata를 어떻게 정의하느냐에 따라 파일 시스템이 다르고, 어떤 것들이 Metadata에 있는지도 다르지만,
대부분 구조는 VBR(Bolume Boot Record), Metadata, Data Blocks로 비슷하다.
- VBR: 현재 파일 시스템이 어떤 파일 시스템인지, 운영체제가 어떻게 이해하면 되는지 알려 줌 (보통 맨 첫 블록 사용)
- VBR 다음부턴 Metadata가 들어가고, Data Blocks가 들어가는데, Metadata와 Data Blocks는 서로 연결되어 있음
- Metadata는 무조건 하나이고, 거기에 따라는 Data Block이 여러 개 있을 수 있음
※ 실제론 Metadata라는 이름을 사용하진 않고, 유닉스, 리눅스 같은 경우엔 inode(아이노드)라는 이름을 사용하는 등 다 다르다.
파일 생성 과정
1. Metadata 하나를 할당 받는다.
2. 파일의 내용을 저장할 수 있는 Data Blocks를 할당 받는다.
3. 해당 Data Blocks에 파일 데이터를 쓴다.
4. Metadata를 업데이트한다.
5. Metadata를 저장 매체에 저장한다.
만약 순서가 바뀌면?
1. Metadata 하나를 할당 받는다.
2. 파일의 내용을 저장할 수 있는 Data Blocks를 할당 받는다.
3. Metadata를 업데이트한다.
4. Metadata를 저장 매체에 저장한다.
5. 해당 Data Blocks에 파일 데이터를 쓴다.
컴퓨터는 항상 모든 처리를 완벽하게 수행하며 올바르게 동작하지는 못하고, 가끔 오류가 날 수 있다.
위처럼, 4번까지 진행되고 컴퓨터가 꺼졌다고 생각해 보면,
실제 데이터, 즉 파일이 없는데도 Metada가 존재하여 파일이 있는 것처럼 오류가 발생한다.
- 공간 비효율적 사용
- 업데이트되지 않은 Data Blocks의 데이터가 실제 데이터인 것처럼 오독
때문에 Metadata보다 Data Blocks에 먼저 써야 한다. (순서 중요)
Metadata를 먼저 쓴 후, 그때 꺼졌다고 생각해 보면, Metadata가 없기 때문에 해당 Data Blocks를 찾을 수 없기에,
전혀 문제 없이 다시 처음부터 진행할 수 있다.
파일 읽기 과정
1. 해당 파일의 Metadata를 찾는다.
2. Metadata에 저장된 Data Blocks의 정보를 가져온다.
3. 해당 Data Blocks의 내용을 읽어서 전달한다.
Metadata 반영
1. 해당 파일의 Metadata를 찾는다.
2. Metadata에 저장된 Data Blocks의 정보를 가져온다.
3. '파일에 접근한 시간' 등을 Metadata에서 수정한다.
4. 해당 Metadata를 저장한다.
5. 해당 Data Blocks의 내용을 읽어서 전달한다.
파일 삭제
생성 및 읽기 과정 중 저장 매체에서 쓰거나 읽는 Metada + Data를 삭제하면 파일은 삭제된다.
문제점
- 1GB 파일을 지우기 위해서는 1GB 파일의 데이터를 지워야 한다.
-> 너무 오래 걸림 (성능적인 이슈)
다 지워야 할까?
Metadata만 지워도 데이터는 다시 복구할 수 없다.
Metadata만 지우기
파일이 어디에 있는지, 크기가 얼마인지, 심지어는 파일이 존재하는지조차 알 수 없다.
파일 복구 원리
파일 삭제
파일을 지울 때 데이터는 성능 이슈로 지우지 않는다.
그래도 Metadata가 없는데 복구가 가능한 이유가 뭘까?
실제 삭제 과정
모든 메타데이터를 지우지 않는다.
예를 들어, FAT에서는 지워진 파일의 시작 위치나 사이즈가 남아있다.
왜냐면 메타데이터를 지우는 것도 일이기에 파일이 있는지, 없는지를 구분하기 위한 데이터 몇 개만 지워버린다.
때문에 시작 위치부터 파일 사이즈만큼 읽으면 파일 복구가 가능하다.
복구가 어려운 경우
- 파일의 메타데이터를 아예 찾기 어려운 경우
- 파일의 데이터가 일부 덮어 씌워진 경우
- 파일이 분할되어 저장된 경우
파일 시스템을 이해해야 하는 이유
- 복구가 될지, 안 될지에 대한 예측 가능
- 정확한 복구를 하려면 파일 시스템을 이해해야 함
카빙(Carving)
전체 디스크를 블록 별로 분석해서 데이터를 복구하는 것을 말한다.
- 블록 별로 저장하니, 완전탐색은 안 해도 된다.
파일 시스템을 몰라도 꽤 많은 데이터를 찾을 수 있지만,
ㄷ메타데이터가 없을 때 해당 파일의 크기를 알기 어렵고, 파일 포멧(e.g, PNG, PDF)을 잘 이해해야 한다는 한계가 있다.
※ 파일 포맷마다 파일을 구분하기 위한 정보를, 그 파일만의 특색있는 정보들이 있기에, 이런 데이터들을 이용하면 해당 파일이 하나의 파일인지, 어떤 파일인지 등을 구분할 수 있다.
디지털 포렌식의 핵심 원리
경찰 수사 과정에서 확보한 원본의 하드디스크나 저장장치 원본은 절대 변경되면 안 된다.
예를 들어, 탐색기에서 폴더를 열기만 해도 마지막 접근 시간(Access Time)이라는 메타데이터가 자동으로 수정되는데, 이는 곧 원본 증거의 훼손으로 간주되어 법적 증거 능력을 상실을 의미한다.
때문에, 메타데이터를 건드지리 않고 파일에 접근해야 한다.
완전 삭제 솔루션
경찰의 반대로, 범죄를 저지른 사람이면 완전 삭제를 해야 하는데, 디스크는 자기 정보이기에 불에 태운다고 해서 변질되지 않아 디스크를 불태우는 정도로는 복구가 가능하다. 또한, 몇 개 비트만 좀 바뀐 것 역시 복구가 가능하다.
그리고 tmp 같은 파일이 남아 있을 수 있기에, tmp 파일도 지우고, 지워지지 않은 데이터 영역 삭제 뿐만 아니라 지워지지 않은 메타데이터도 모두 삭제해야 완전 삭제가 된다.
이때 거대한 파일로 데이터를 덮어 씌운다면 삭제는 아니지만 복구는 어렵다.
SSD & HDD

▶ SSD 저장장치
- Chip: 일반적인 SSD
※ Spare Area: 오류 체크를 목적으로 함
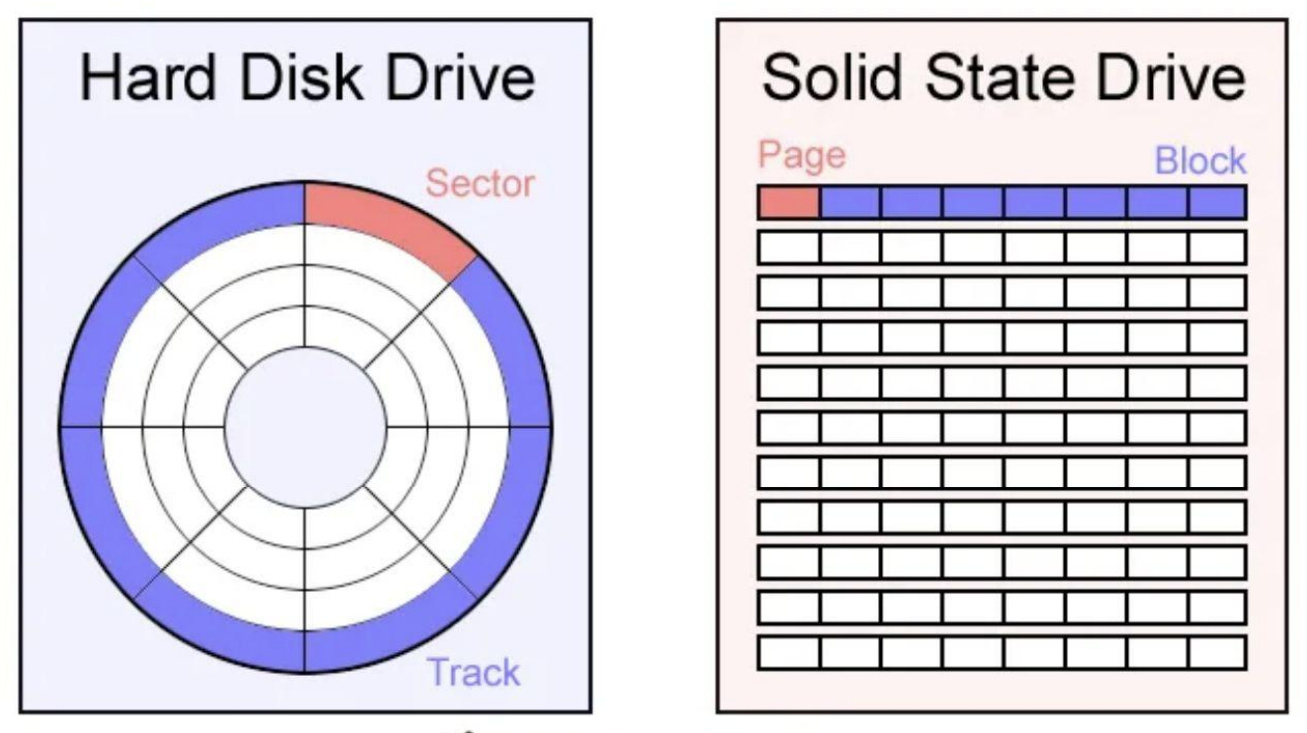
▶ HDD vs SSD
- SSD: Block 안에 Page가 존재
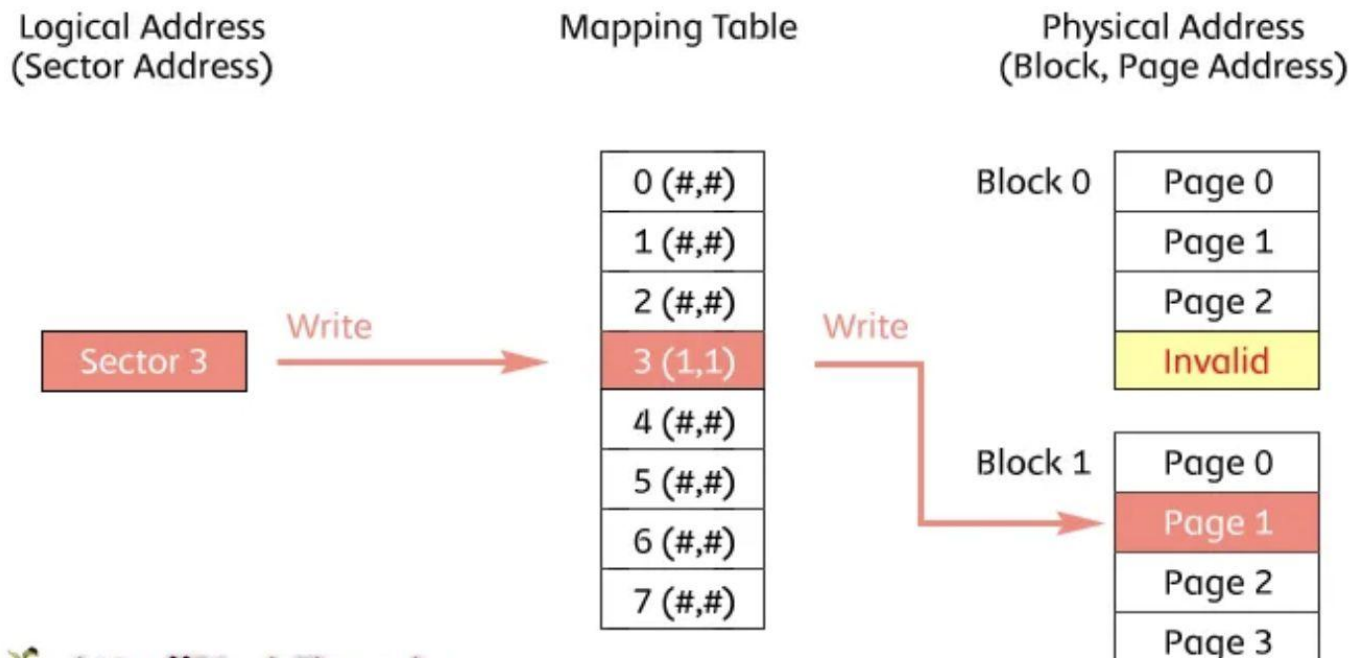
FTL (Flash Translation Layer)
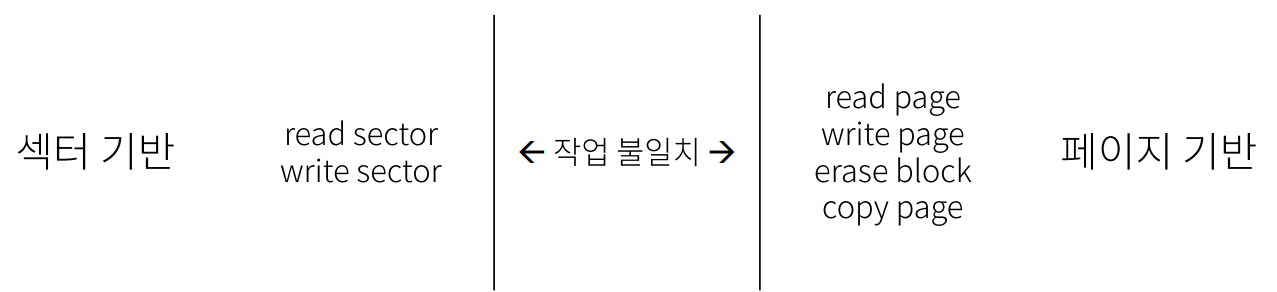
▶ SW는 섹터를 기반으로 저장, SSD는 블록과 페이지를 기반으로 저장, 이 중간을 맞춰주기 위함
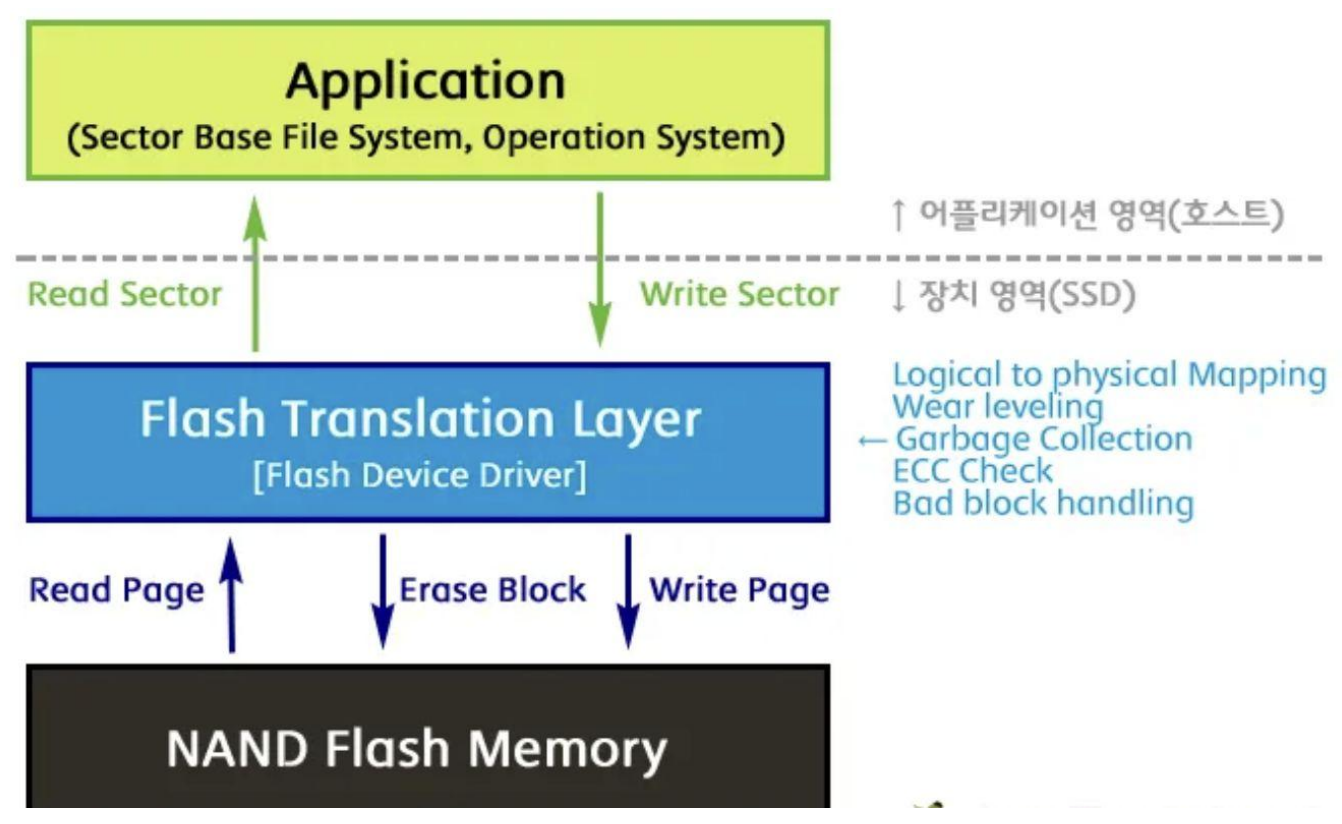
▶ 어플리케이션과 SSD 사이에서 FTL이 번역 (주소 매핑)

▶ 어플리케이션은 가상의 섹터를 사용하고, 실제 SSD는 FTL을 통해 페이지와 블록들을 접근
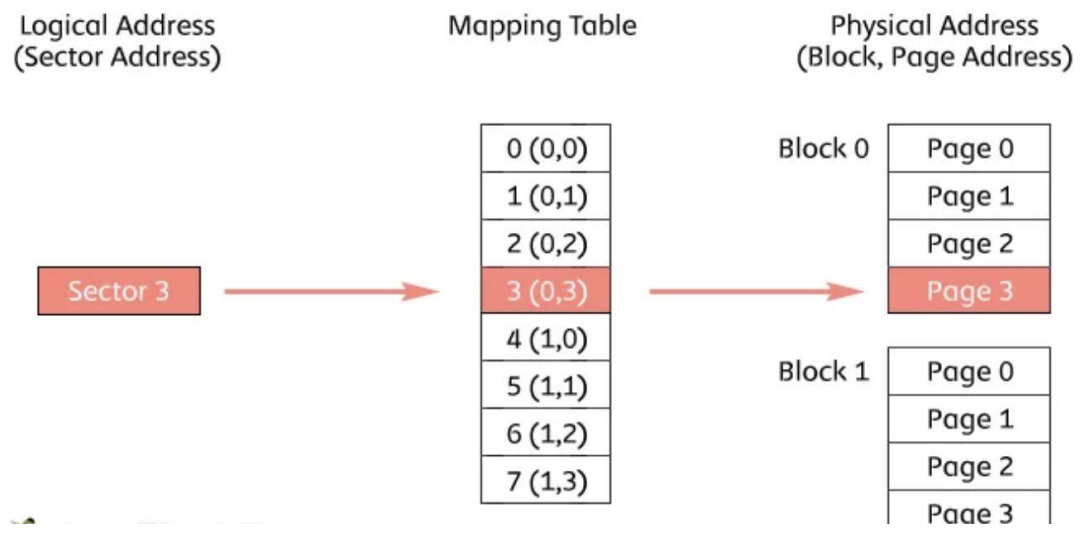
FTL 웨어 레벨링
NAND 플래시는 블록을 일정 횟수 이상 지우면 수명이 망가진다. (-> 읽기, 쓰기 횟수 제한)
- 특정 블록만 자꾸 쓰고 지우면 빠르게 망가짐 (하나의 블록이라도 읽기 쓰기 횟수 제한 끝나는 순간 SSD 자체가 끝)
- 웨어 레벨링: FTL이 쓰기 위치를 분산시켜 모든 블록이 고르게 마모되도록 하는 기술
삭제하면?
- FTL에서 논리적 주소만 무효화함
- 웨어 레벨링 알고리즘이 다음 데이터 저장 위치를 사용 빈도가 낮은 블록으로 유도
- 결과적으로 모든 블록이 비슷한 횟수만큼 지워지고 쓰이도록 관리

| 구분 | 설명 | 일반 크기 |
| 페이지 (Page) | 읽기/쓰기의 최소 단위 | 보통 4KB ~ 16KB |
| 블록 (Block) | 삭제의 최소 단위, 여러 페이지로 구성됨 | 보통 128 ~ 512 페이지, 즉 512KB ~ 8MB |
| 플레인/다이/칩 | 병렬화 단위로 위 구조들을 묶는 상위 계층 |
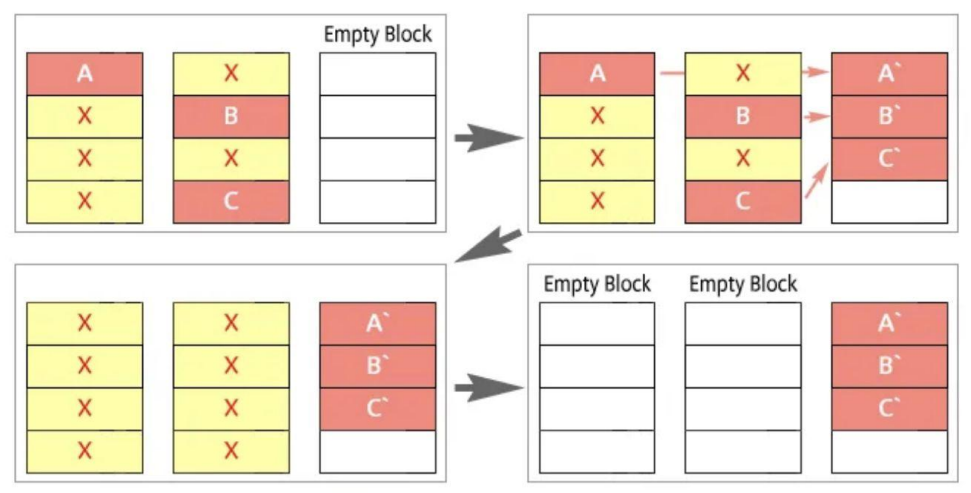
▶ 가비지 컬렉션: 비효율적으로 저장된 구조 해결
오버 프로비저닝
SSD의 제약에 의해 처리 과정에서 저장 공간이 필요하다. 이때 성능을 높이려면 항상 빈 공간이 있어야 한다.
이러한 빈 공간인 오버 프로비저닝 공간을 만들어 둬서, 저장 공간이 모두 사용되는 것 방지한다.
- ex) 256GB인 SSD에서 240GB만 제공, 나머지 16GB는 FTL, 가비지 컬렉션, 웨어 레벨링 등에 사용
결론
SSD는 복구가 더 어렵다. 특히 FTL은 공개되지 않은 자료라서 더 어렵다.
과제
사진에 숨은 글자 찾기
JPG 파일에 두 개의 숨겨진 메시지 찾기
- 숨겨진 메시지 형식: KHU{숨겨진 메시지}
- HxD같은 hexa tool을 이용하면 편리
- 힌트: jpg 파일 구조 알아보기, 파일 용량이 겉보기보다 큼
1. ctrl + F로 KHU 검색
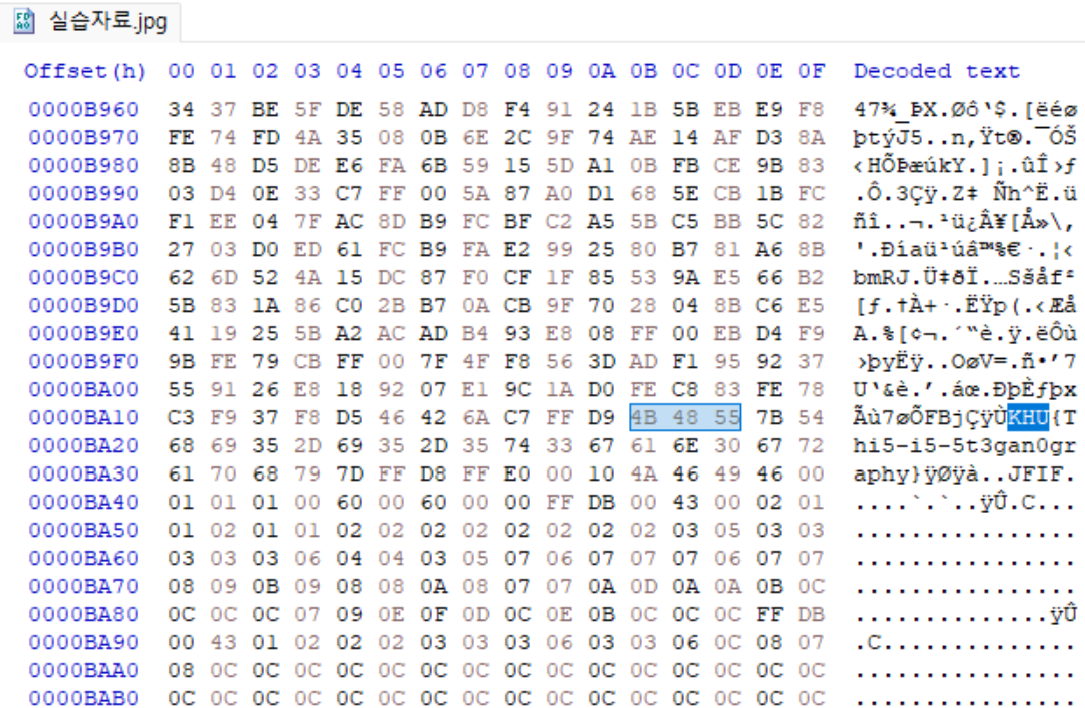
▶ KHU{Thi5-i5-5t3gan0graphy}
2. JPG 파일 구조 이용
- JPG 파일 시작: ff d8
- JPG 파일 끝: ff d9

▶ 처음 찾은 플래그를 가운데 두고 두 개의 JPG 파일 구조가 보임을 확인

▶ 두 번째 JPG 파일을 추출
- 두 번째 JPG 파일 복사
- 파일 - 새로 만들기 후, 붙여넣기
- 다른 이름으로 저장
- 저장한 파일을 이미지로 열기 - Windows 사진 뷰어
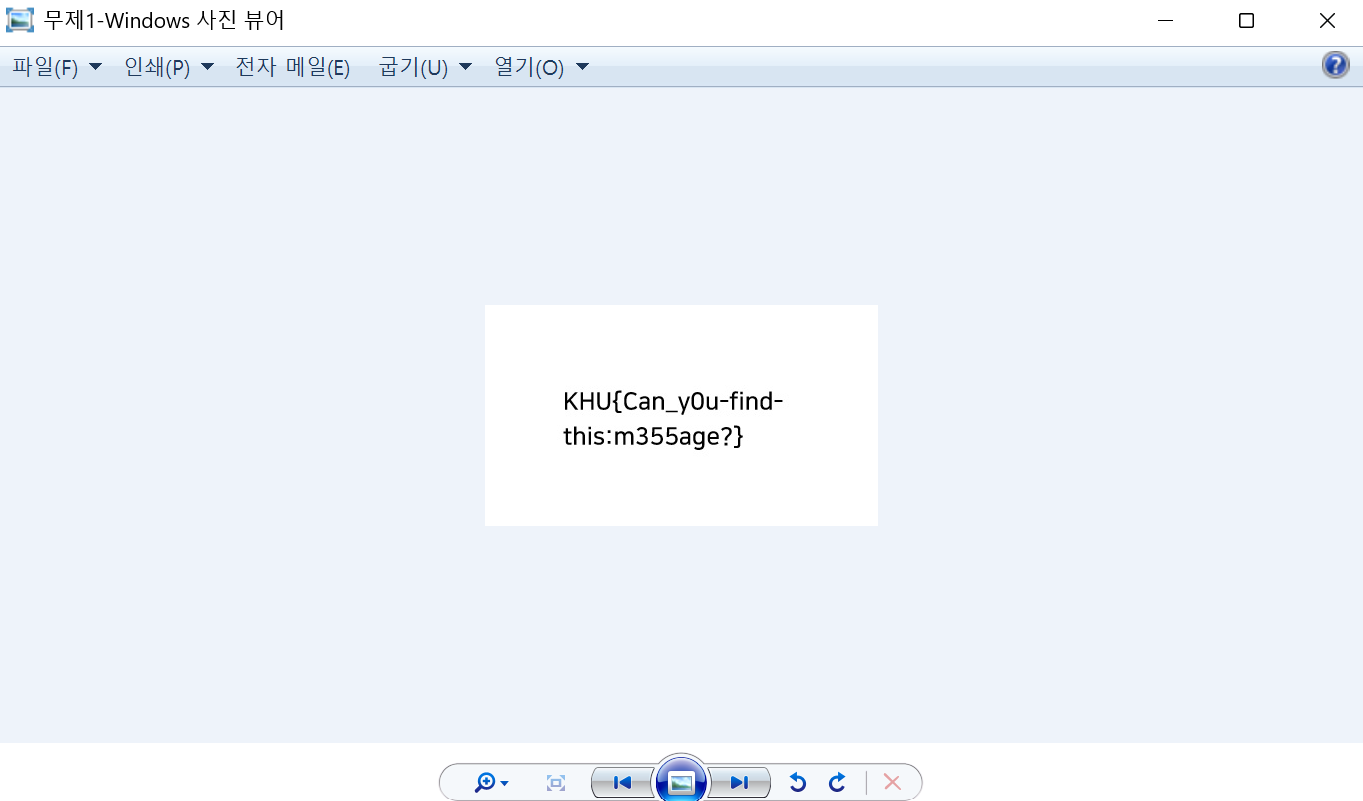
▶ KHU{Can_y0u-find-this:m355age?}
참고자료
https://www.youtube.com/watch?v=m2NfFJEvssY&list=PLVsNizTWUw7FCS83JhC1vflK8OcLRG0Hl&index=20
https://m.blog.naver.com/tptptpduf/222089445505
운영체제 - 22 : 디스크 관리
이 포스팅의 내용은 『운영체제와 정보기술의 원리』 책과 반효경 교수님의 강의를 통해 배운 내용을 정리...
blog.naver.com
JPG 파일 구조 분석 #1
JPEG는 이미지 파일 형식이 아니라 알고리즘이다. 보여지는 JPEG 이미지는 내부적으로 JPEG 압축 알고리즘을 사용하는 JFIF 형식(JPEG File Interchange Format)이다. 앞의 포스팅에서 보여준 파일을 다시 한
delock.tistory.com
https://velog.io/@vina1601/5%EC%A3%BC%EC%B0%A8-%EA%B3%BC%EC%A0%9C
포렌식 개념과 문제 풀어보기
디지털 포렌식 포렌식 먼저 '포렌식'은 고대 로마시대의 '포럼'이라는 단어에서 유래한 단어로 범죄수사 및 민/형사 소송 등 법정에서 사용되는 증거의 수집, 분석, 보존 등등을 위한 응용 과학
velog.io
'Security > 정보보안' 카테고리의 다른 글
| XSS game (1) | 2025.04.01 |
|---|---|
| 정보보안 3차시: 웹 - SQL Injection (3) | 2025.03.31 |
| 정보보안 2차시: 웹 - 기본적인 웹 취약점 (2) | 2025.03.28 |
| 정보보안 1차시: 네트워크 - ARP와 TCP/UDP (5) | 2025.03.21 |