경희대학교 김정욱 교수님의 컴퓨터 구조 수업을 기반으로 정리한 글입니다.
Overview of Pipelining
Pipelining

▶ Pipelining - Laundry Example
- 동기: 직렬적으로 작동하는 방식으로, 하나의 task가 끝날 때까지 기다렸다가 다음 task가 실행된다.
- 비동기: 병렬적으로 작동하는 방식으로, 한 번에 여러 task가 동시에 병렬적으로 실행된다.
Pipelining 기법은 여러개의 명령어를 비동기로 처리하는 기술로, 속도가 빠르다는 장점이 있다.
여러 instruction이 overlapped 되도록, 즉 동시에 수행하도록 하는 implementation technique (구현 기술)이다.
※ single cycle path 방식 (하나의 instruction이 끝나야 그다음 instruction 수행)보다 pipelinig 방식이 더 효율적이다.
Pipeline Instruction-execution (5 stages)
1. Fetch instruction from memory: Fetch
2. Read registers while decoding the instruction: Decode
3. Execute the operation or calculate an address: Execute
4. Access an operand(피연산자) in data memory: Access Memory
5. Write the result into a register: Write Back
⭐ Instruction class별 Total time
▶ single cycle
※ 각각의 단계마다 시간이 다르다.
single cycle일 경우
- lw는 모든 5가지 stage를 다 거쳐야 하기에 800 피코초(ps)가 걸린다.
- sw는 Register write를 제외한 4가지 stage를 거쳐야 하기에 700 피코초가 걸린다.
- R-format은 memory에 data access를 제외한 4가지 stage를 거쳐야 하기에 600 피코초가 걸린다.
- beq는 data access, register wirte를 제외한 3가지 단계를 거쳐야 하기에 500 피코초가 걸린다. (가장 빠르다.)
※ Instruction fetch와 Register read는 어떤 명령어든 무조건 실행해야 하는 단계이다.
single cycle로 구현시, lw가 가장 느리고 beq가 가장 빠르며,
pipelined로 구현시 total time이 다 동일하다.
※ pipelined로 구현할 경우엔 instruction에 따라 어떤 단계는 가고, 어떤 단계는 안 가고, 이런식으로 나눌 경우 꼬인다. 때문에 전 단계를 모두 동일하게 가는 방식으로 구현하여 시간이 동일한 것이다.
Pipelining Speed-Up Discussion
⭐ Single cycle vs. Pipelined performance
▶ Single cycle vs. Pipelined performance
※ $0는 $t0을 생략해서 표현한 것이다.
※ single cycle의 경우에 lw -> sw -> lw가 실행되면 총 걸리는 시간은 800 + 700 + 800이다.
Problem
fetch 단계는 200ps, Register file에서 decode 단계는 100ps가 걸린다.
때문에 첫 번째 instruction에서 decode 단계가 끝났다고 ALU에서 Execute 단계로 가면 꼬여버리게 된다.
즉, Pipelined 기법은 각각의 단계에서 하나씩만 할 수 있어야 하는데, 이를 고려하지 않으면 꼬이게 된다. (겹치면 X)
Solution
가장 오래 걸리는 시간을 기준으로 다음 단계로 넘어가면 된다.
Example
1단계: 100 / 2단계:300 / 3단계: 200 / 4단계: 500 / 5단계: 200
이 경우, 1단계와 2단계만 봤을 땐 300으로 맞추면 될 것 같다고 생각할 수 있다.
하지만 instruction이 아직 뒤에까지 안 갔더라도, 5단계 중 가장 긴 단계를 기준으로 무조건 맞춰야 한다.
그 이유는 처음엔 300으로 맞췄다가 나중에 500으로 맞추고, 이런 식으로 기준을 바꾸면 꼬여버리게 된다.
그래서 결국, 이 예시에선 500으로 맞춰야 한다.
500으로 맞춤으로써 기준보다 시간이 적게 걸리는 단계들은 남는 시간에 쉬어준다.
예를 들어, 2단계의 경우 앞에 200ps는 쉬고 뒤에 300ps만 단계를 수행한다.
시작과 끝 단계도 동일하게 가장 긴 단계에 맞춰주어야 한다. 이렇게만 보면 손해일 수 있지만, pipelined 기법을 통해 충분히 효율화했기에 이 정도 손해는 안고 간다.
※ 쉬는 시간은 앞이든, 뒤이든 상관없다. 단지 주어진 시간 안에만 수행하면 된다.
Pipelining speed-up
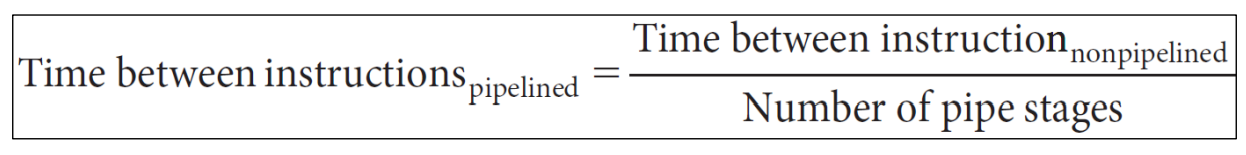
▶ If the stages are perfectly balanced, then the difference time between instructions on the pipelined is as follows
※ balanced의 의미는 모든 단계의 time이 전부 동일하다는 의미이다.
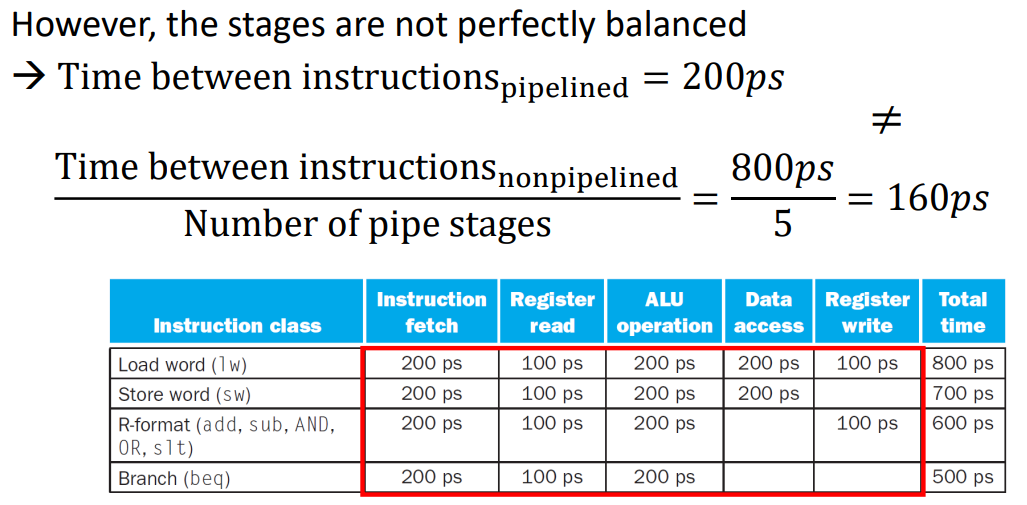
▶ However, the stages are not perfectly balanced -> 좌항과 우항 값 같지 X (lw 예시)
※ nonpipelined = single cycle

▶ lw 예시
instruction 개수가 많아질 수록, nonpipelined의 속도가 느려지게 된다.
pipelined는 nonpipelined보다 속도가 4배 정도 빠르다.
이렇게 속도가 매우 빨라진다는 장점이 있는 반면, 이 단계들이 겹쳐지면 문제가 된다는 단점도 있다.
Pipelined Datapath and Control
5 stages of Pipelining
1. IF: Instruction fetch
2. ID: Instruction decode and register file read
3. EX: Execution or address calculation
4. MEM: Data memory access
5. WB: Write back (right to left)
※ 1 ~ 4 단계는 모두 left to right 방식이다.
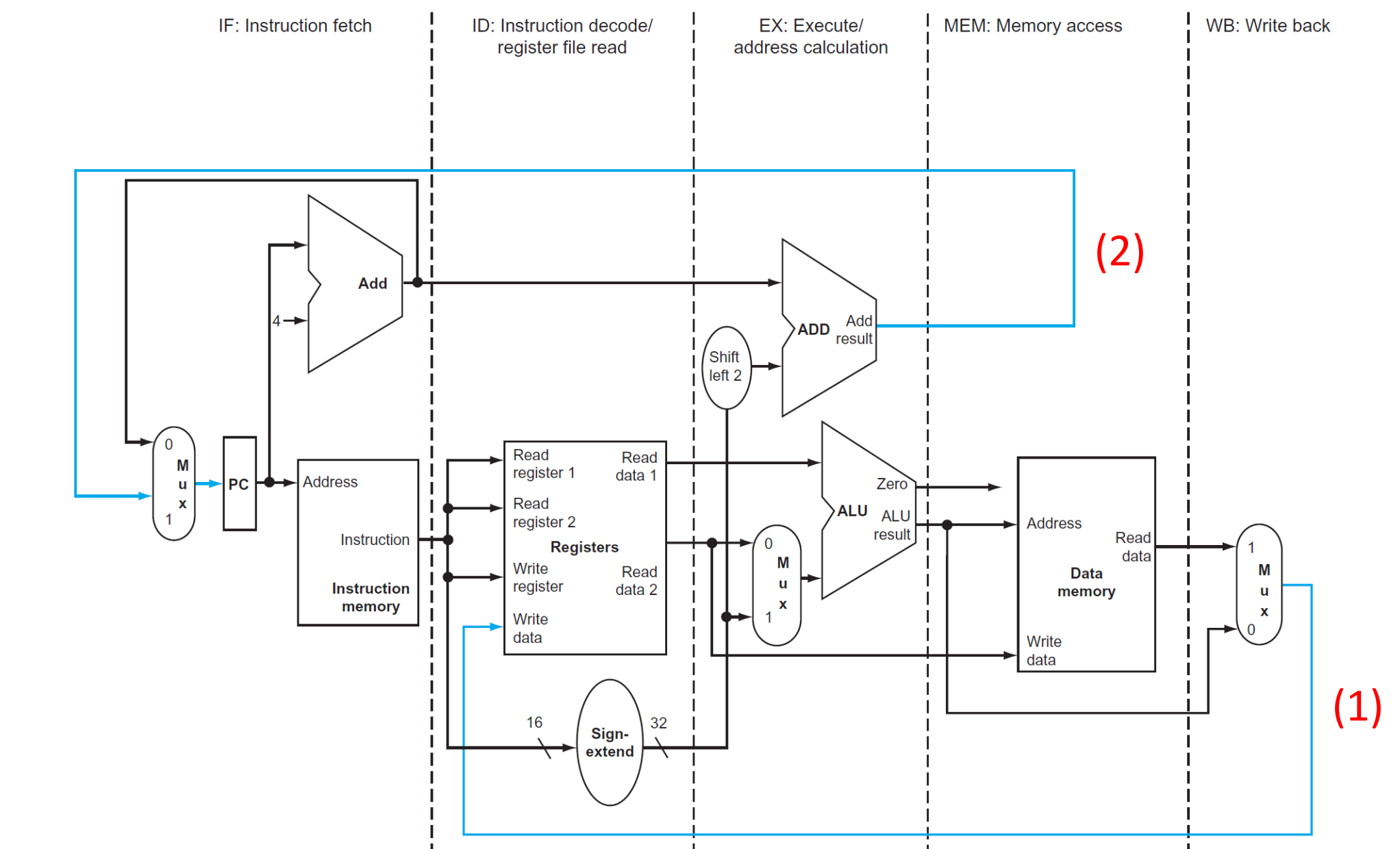
▶ 5 stages of Pipelining
instruction들은 보통 left to right 방향으로 진행되지만, 두 가지 예외가 있다. (right to left)
- (1) Write-back (WB) stage: It places the result back into the register file
- (2) The selection of the next value of the PC (새로운 PC 값으로 업데이트하는 단계)
Pipeline datapath with pipeline register
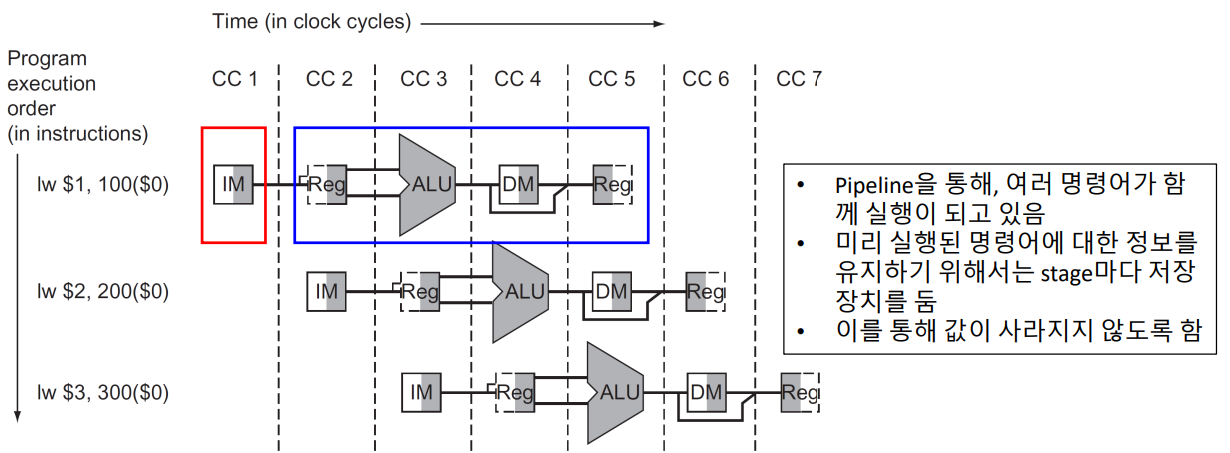
▶ Pipeline register
Problem
첫 번째 instruction에 대해 Register file이 decoding을 하는 시점에서,
IM은 두 번째 instruction을 Fetch 하기 위해 output으로 두 번째 instruction을 꺼내 놓는다.
때문에 Register file 입장에서는 첫 번째 instruction에 대해 decoding 해서 결과를 내야 하는데,
두 번째 instruction에 대해서도 Fetch가 되어 값을 보내버리니 신호 두 개가 섞여 꼬이는 문제가 발생한다.
즉, CC2의 IM이 Fetch되면 CC1의 IM은 제거될 수 있다.
Solution
이러한 문제점을 해결하기 위해 pipeline register를 둔다. (pipeline register: 위 그림에서 세로 점선)
pipeline register는 미리 온 instruction을 처리할 때까지 다음 instruction 신호(32 비트 값)를 임시적으로 저장한다.
이는 각 단계마다 있어, 그 다음 값을 저장했다가 넘겨준다. (댐 역할)
즉, pipeline register는 각각의 단계에서 서로 다른 instruction을 수행하고 있기 때문에 이를 막아주는 역할을 한다.
만약, 이를 막아주는 pipeline register가 없으면 신호가 연결이 되어 섞이게 된다.
※ IM: Instruction Memory / CCn: clock cycle n
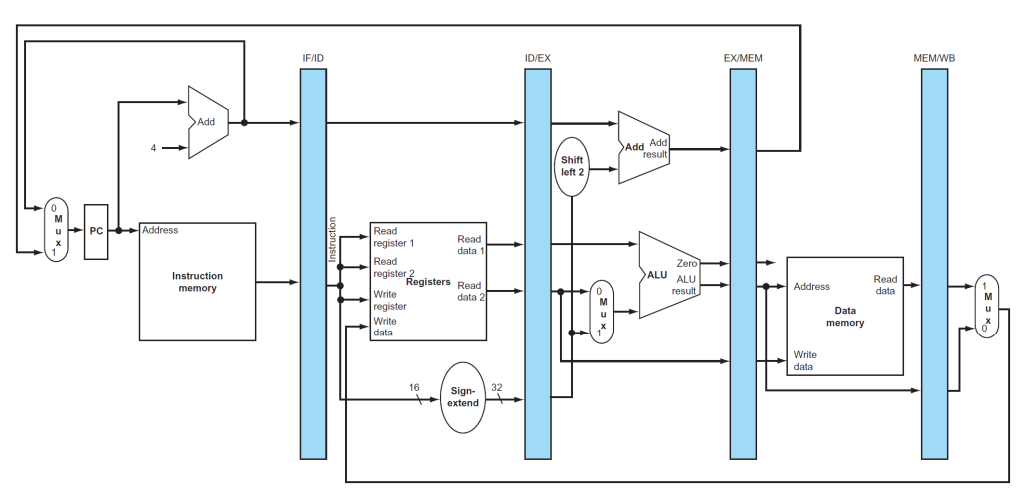
▶ Pipelined datapath
pipeline register는 WB stage를 제외한 매 단계마다 있다.
-> pipeline register: IF/ID, ID/EX, EX/MEM, MEM/WB
※ 그림 속에서 파란 색 막대기(댐 같은)가 pipeline register을 의미한다. 이게 없는 그림은 single cycle datapath이다.
pipeline register에는 무슨 값이 저장이 될까?
※ control signal도 pipeline register에 저장된다.
1. Five stages: lw instruction
(1) Instruction fetch
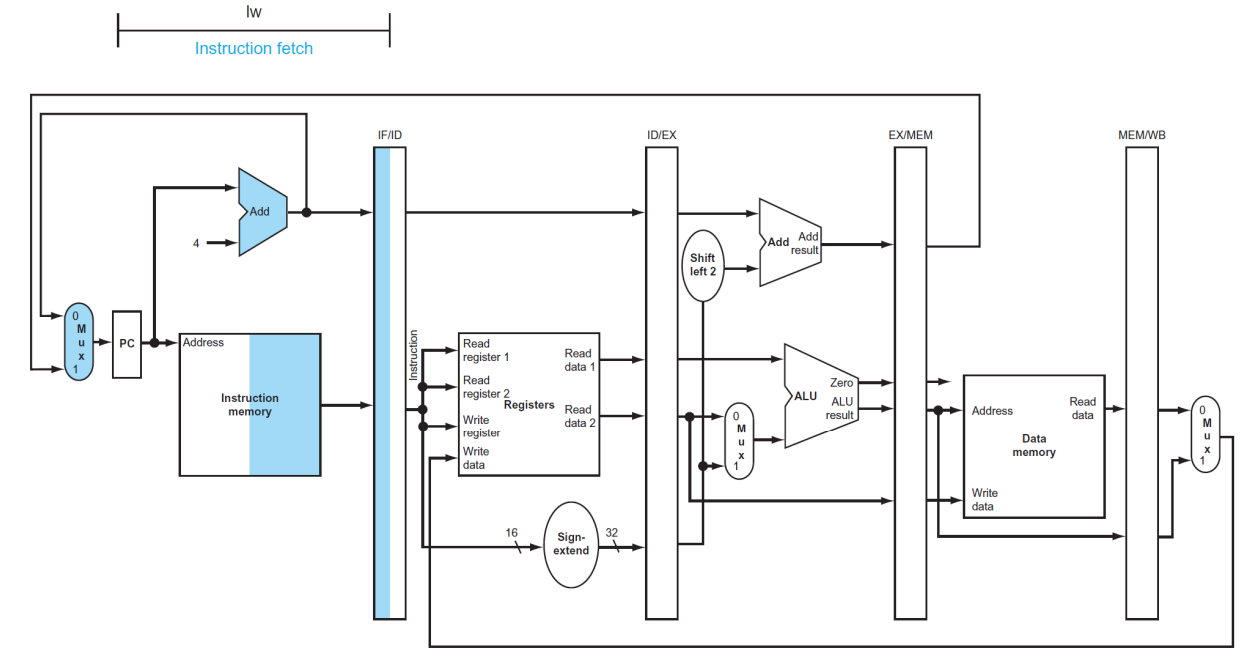
▶ IF
IF/ID
- PC + 4 값, Decoding을 할 instruction 값을 저장한다. (이때 PC + 4의 MUX는 MUX 신호가 올 때 활동한다.)
- PC + 4 값은 beq, jump와 같이 PC + 4 값을 필요로 하는 명령어를 위해 저장된다.
※ 파란색 부분이 현재 activate되어 있는 부분이고, 노란색 하이라이트 부분으로 표시된 값이 유효한 값이다.
※ PC + 4 값으로 바로 가지 않고 저장하는 이유는, 아직 instruction이 decode되어 있지 않아 뒤에 무슨 일이 벌어질지 모르기 때문이다.
(2) Instruction decode and register file read
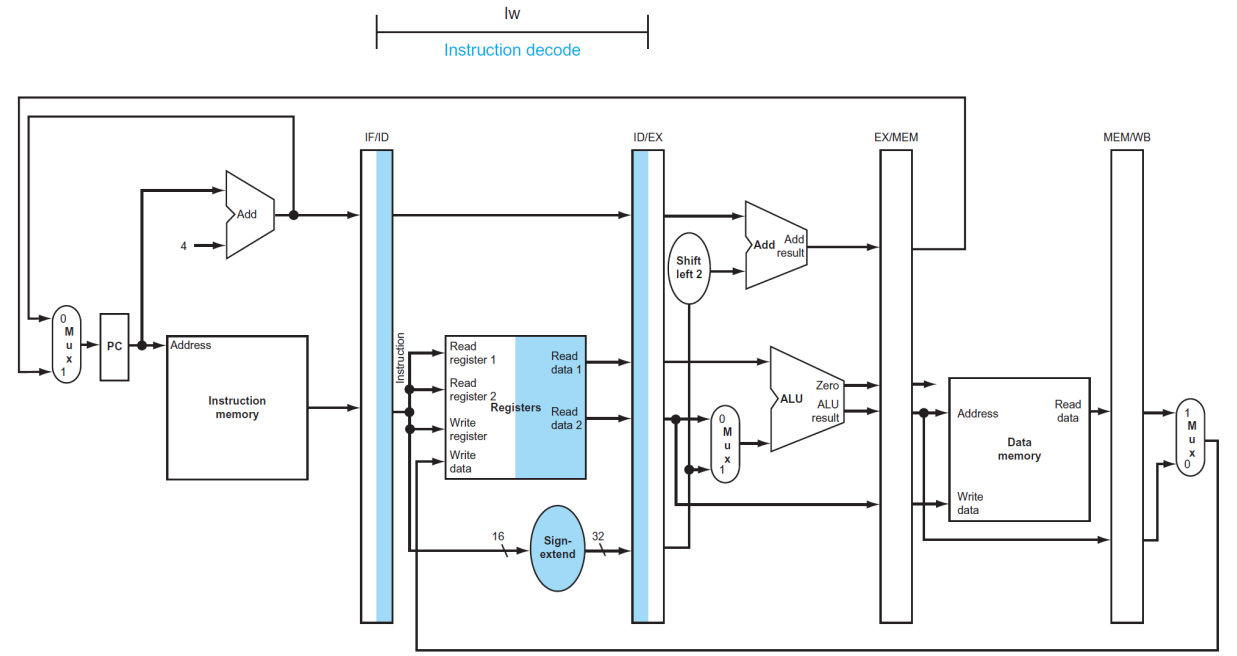
▶ ID
ID/EX
- IF/ID pipeline register에 기반하여 3개의 값을 저장한다. (sign-extend 32-bits, read data 1, read data 2)
- 증가된 PC 값도 저장한다.
(3) Execute or address calculation
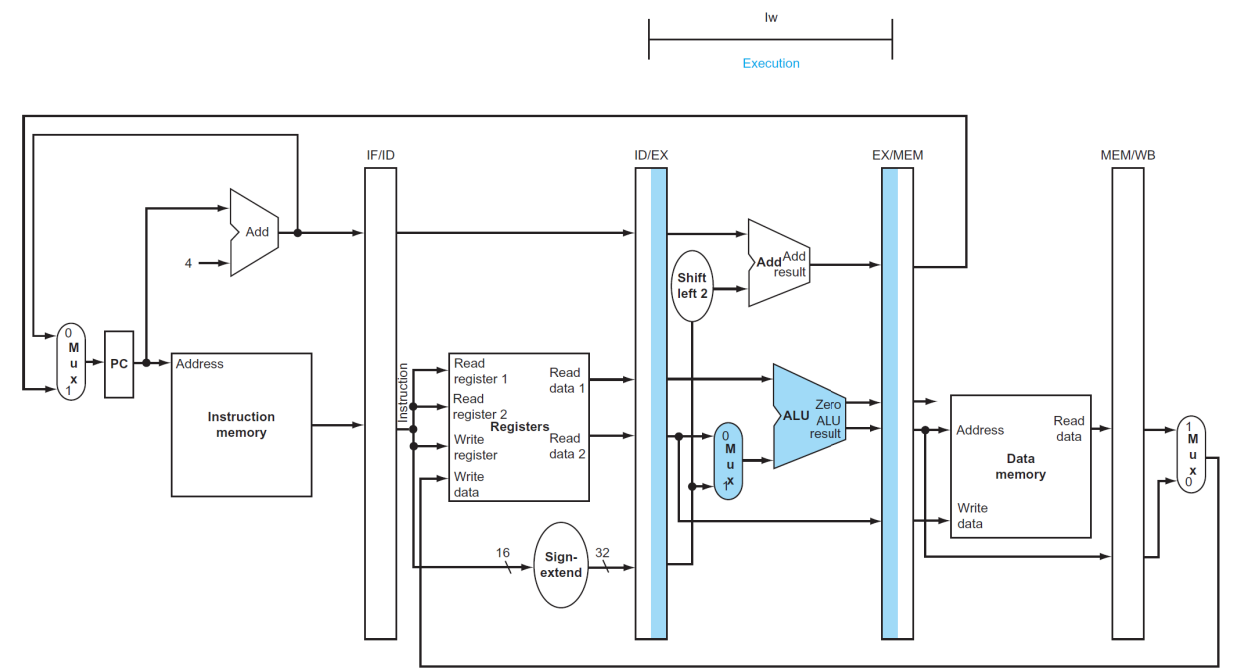
▶ EX
EX/MEM
- ID/EX pipeline register에 기반하여 4개의 값을 저장한다. ((PC + 4) + sign-extend 32-bits, Zero, ALU result, read data 2)
(4) Memory address
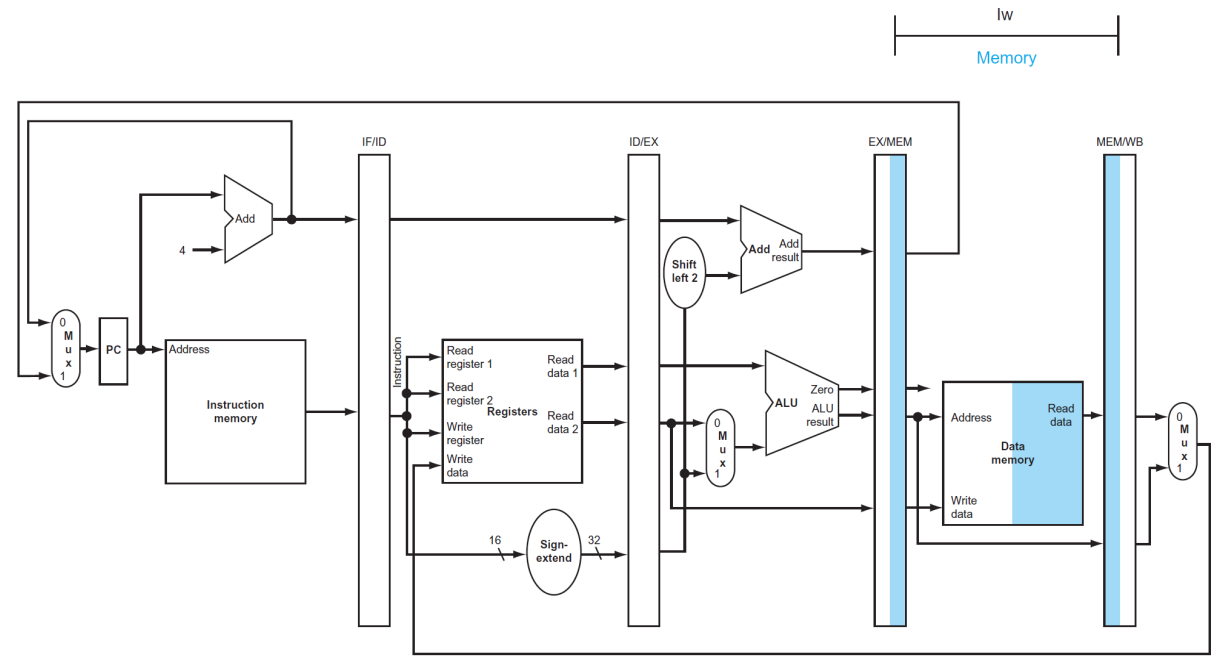
▶ MEM
MEM/WB
- EX/MEM pipeline register로부터 얻은 address를 이용하여 메모리로부터 읽은 데이터를 저장한다. (Read data)
- WB에 사용할 ALU result도 저장한다.
(5) Write-back
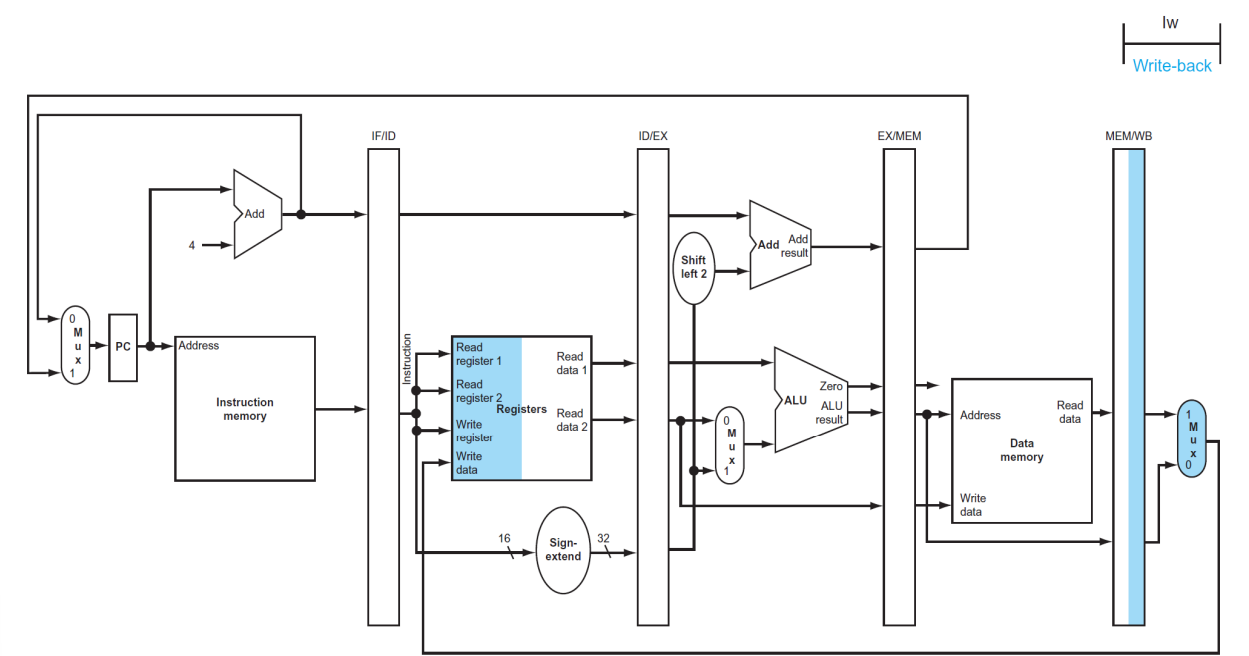
▶ WB
Read data or ALU result를 받아 Register file에 저장한다. (Write data)
2. Five stages: sw instruction
(1) Instruction fetch
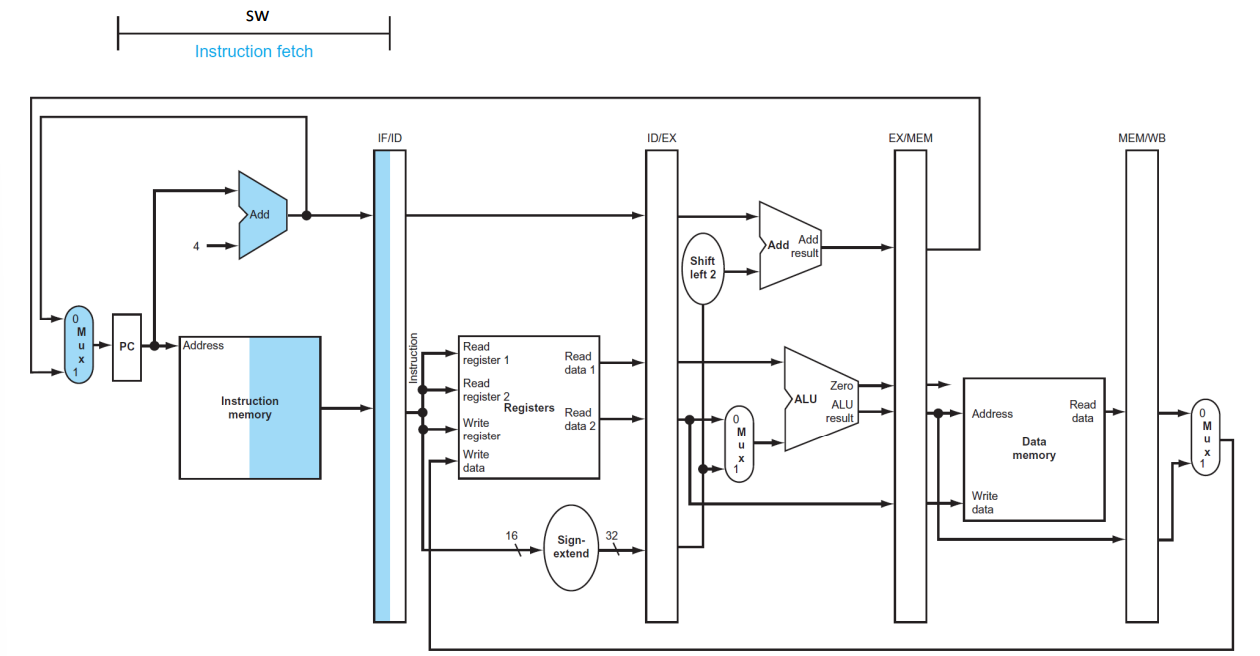
▶ IF
IF/ID
- PC + 4 값, Decoding을 할 instruction 값을 저장한다. (이때 PC + 4의 MUX는 MUX 신호가 올 때 활동한다.)
- PC + 4 값은 beq, jump와 같이 PC + 4 값을 필요로 하는 명령어를 위해 저장된다.
(2) Instruction decode and register file read
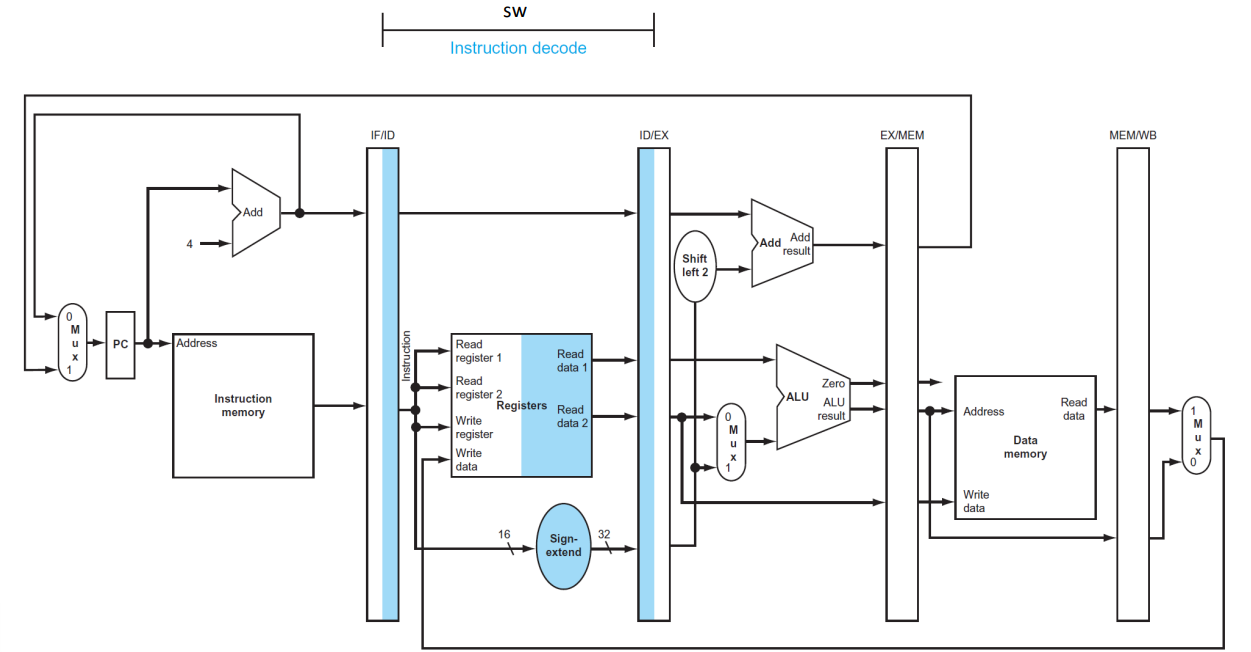
▶ ID
ID/EX
- IF/ID pipeline register에 기반하여 3개의 값을 저장한다. (sign-extend 32-bits, read data 1, read data 2)
- 증가된 PC 값도 저장한다.
(3) Execute or address calculation
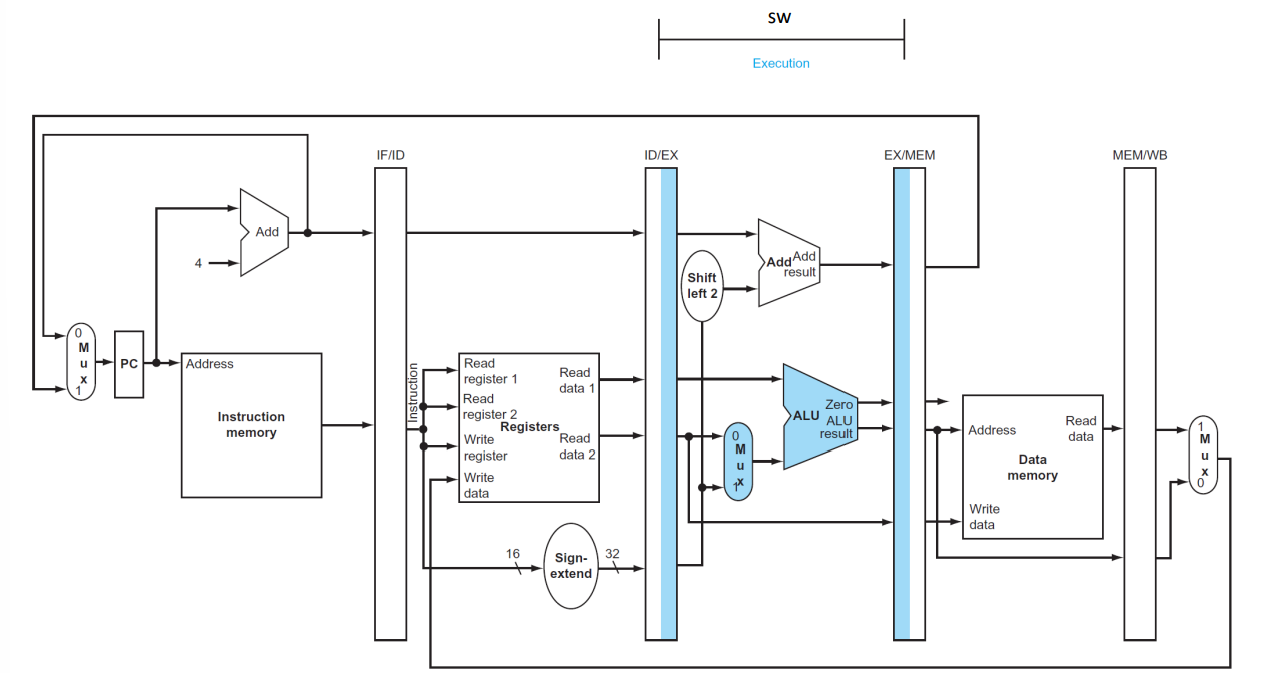
▶ EX
EX/MEM
- ID/EX pipeline register에 기반하여 4개의 값을 저장한다. ((PC + 4) + sign-extend 32-bits, Zero, ALU result, read data 2)
(4) Memory address
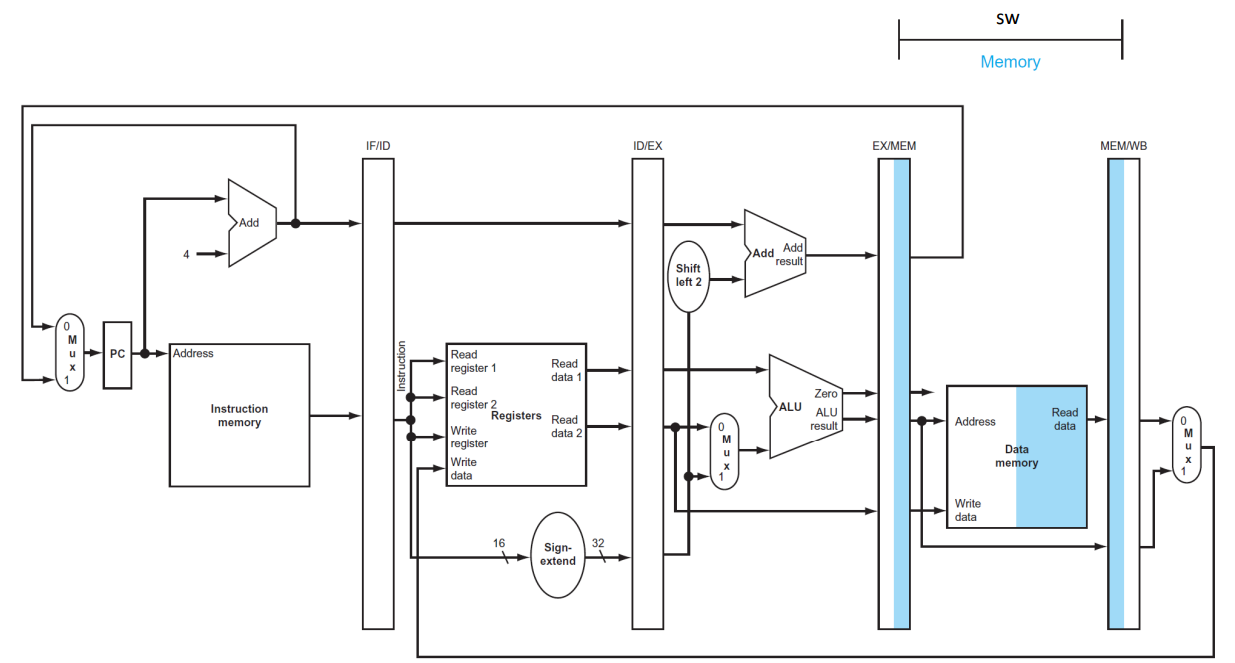
▶ MEM
MEM/WB
- EX/MEM pipeline register로부터 얻은 address를 이용하여 메모리로부터 읽은 데이터를 저장한다. (Read data)
- WB에 사용할 ALU result도 저장한다.
(5) Write-back
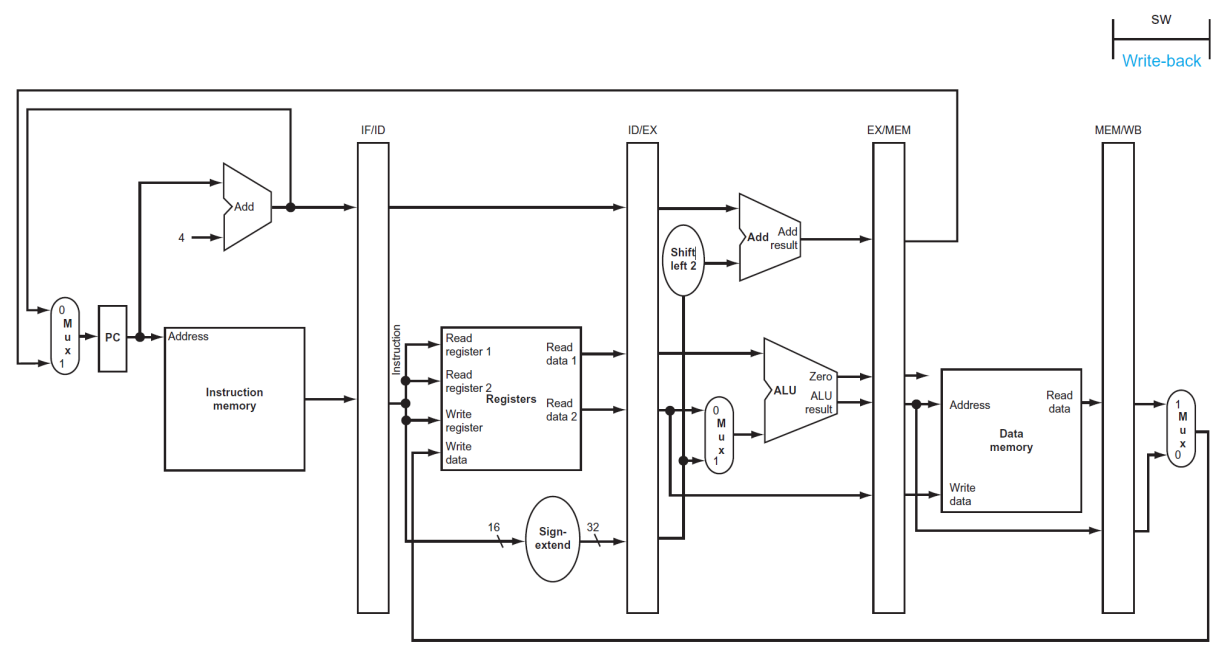
▶ WB
Don't care에 의해 sw가 관심 없는 아무 신호가 전달될 것이긴 하나, 유효한 값이 아니다.
즉, 관심있는 일은 아무 일도 일어나지 않는다.
Graphically Representing Pipelines
Two basic styles of Multiple clock cycle pipeline diagram
First basic style
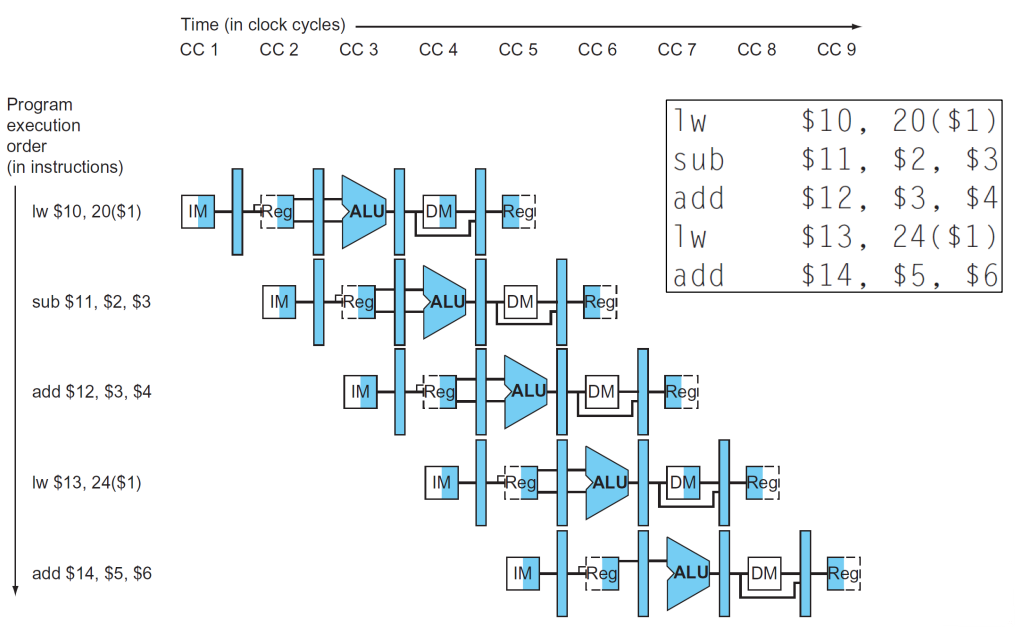
▶ It does not contain all the details
※ sub의 경우 MEM 단계가 필요없으므로 다른 단계들이 처리되는 동안 그냥 기다리면 된다.
Second basic style
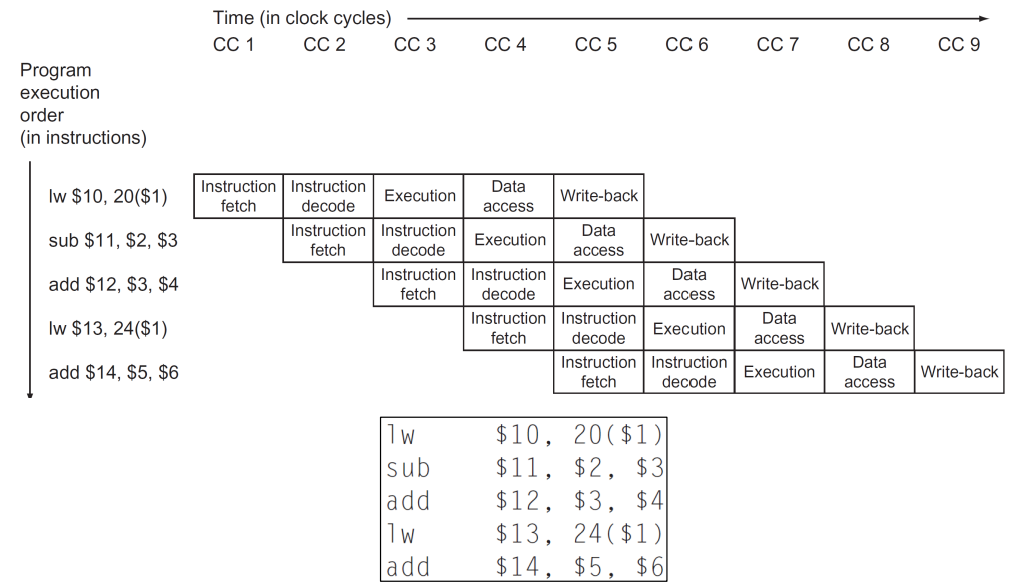
▶ It contains all the details (the name of each stage), and it is more traditional version
※ 실제로 diagram을 그릴 땐 second basic style로 그리면 된다.
Pipelined Control
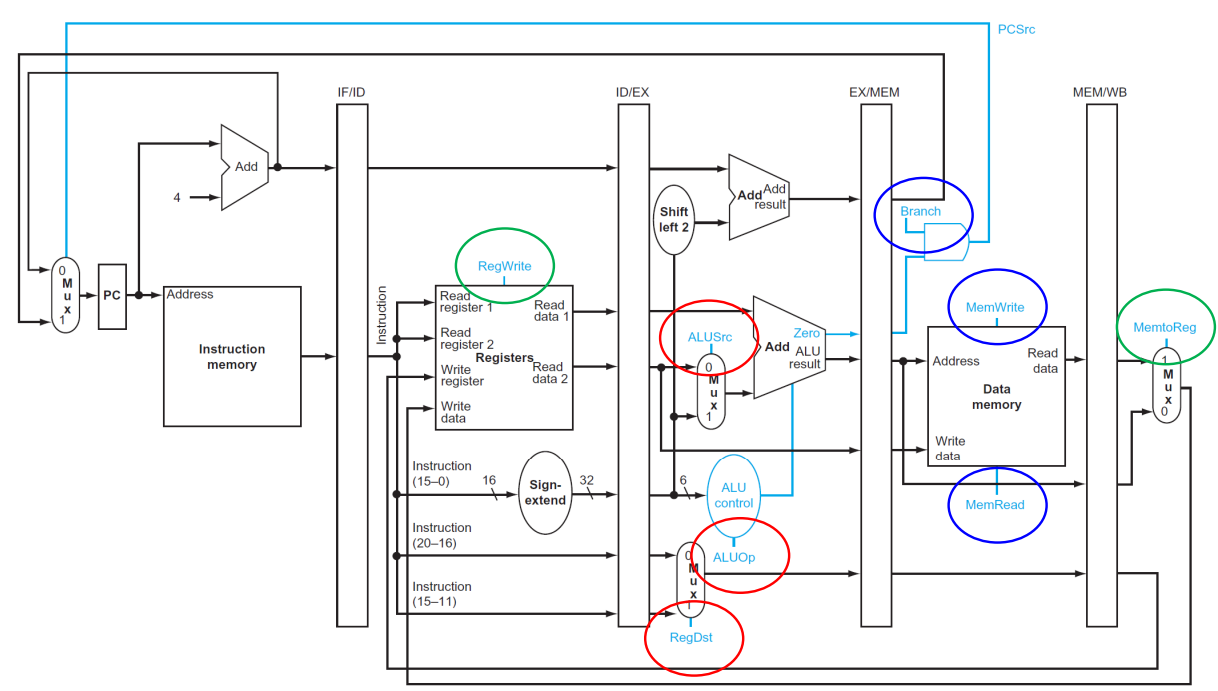
▶ control signal
control signal도 pipeline register에 저장해야 한다.
그 이유는 각각의 control signal이 필요한 단계 및 위치가 다른데, 이렇게 각각의 위치에서 필요한 단계가 올 때까지 저장을 해서 보내주어야 하기 때문이다. (control signal이 꼬이지 않도록 하기 위해 저장한다.)
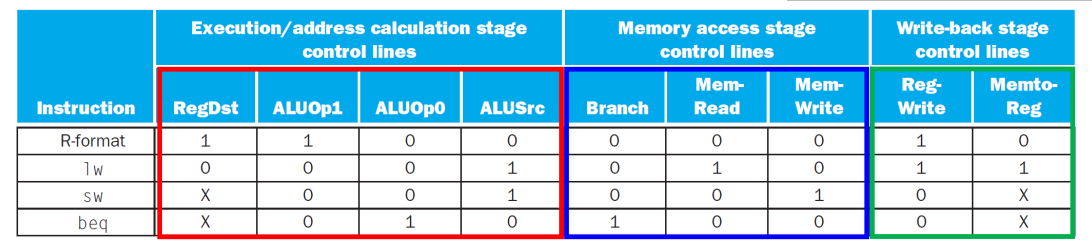
▶ EX / MEM / WB 각각의 단계에 필요한 control signal
- 빨간색 부분: EX 단계까지만 보존
- 파란색 부분: MEM 단계까지만 보존
- 초록색 부분:끝까지 보존, 즉 모든 파이프라인 레지스터 각각의 단계에서 계속 보존을 해주어야 한다.
Reg-Write signal은 위치상 ID 단계에 필요할 것 같지만 실제론 WB 단계에 필요하다.
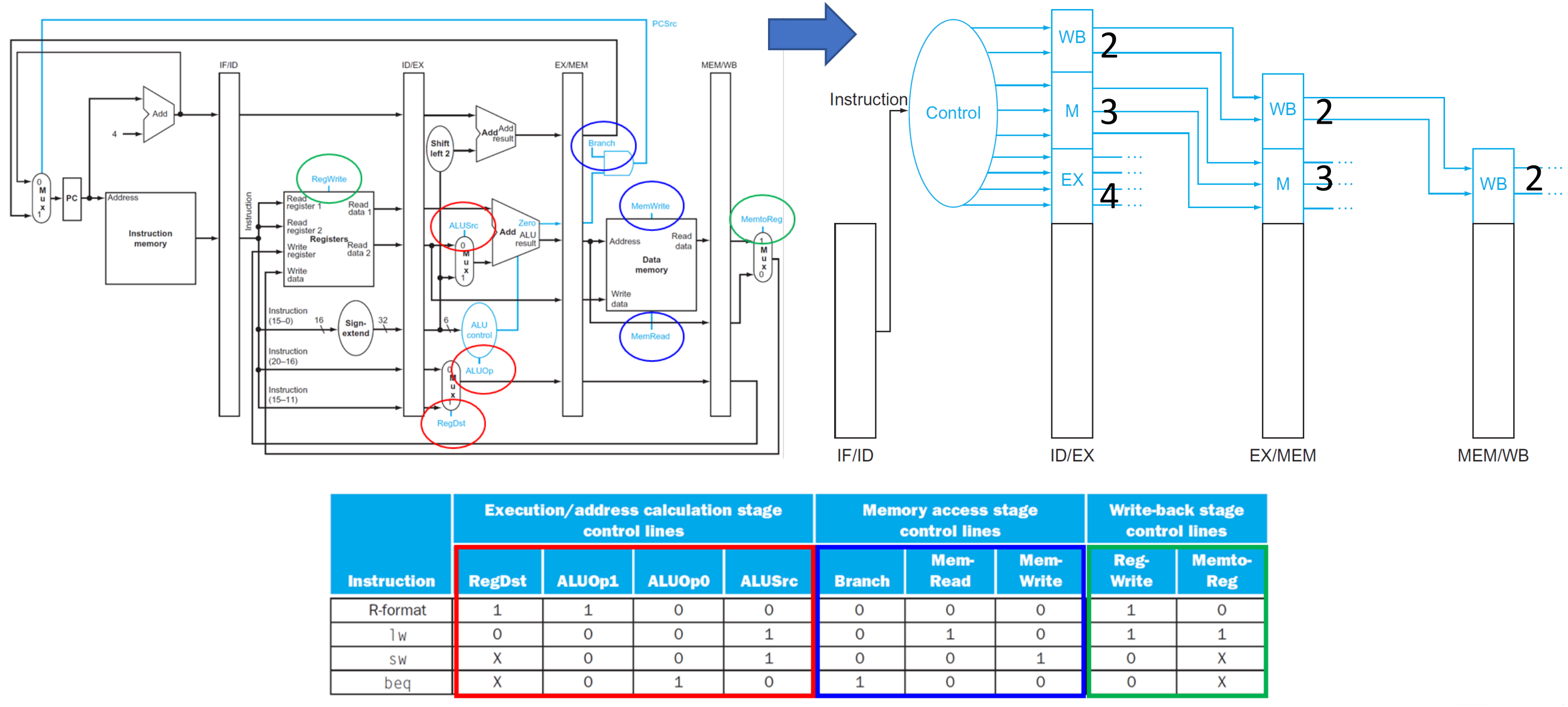
▶ control signal in pipeline register
control signal은 IF 되자마자 ID에서 instruction의 opcode 6비트에 따라 결정된다.
그리고 이렇게 결정된 control signal을 pipeline register에 저장해 control signal을 보낸다.
'CS > 컴퓨터 구조' 카테고리의 다른 글
| Lecture 16: The Processor - 5 (2) | 2024.12.06 |
|---|---|
| Lecture 15: The Processor - 4 (0) | 2024.12.03 |
| Lecture 13: The Processor - 2 (0) | 2024.11.29 |
| Lecture 12: The Processor - 1 (0) | 2024.11.27 |
| Lecture 10: Arithmetic for Computers - 2 (0) | 2024.10.17 |